阅读笔记-Frame-wise Motion and Appearance for Real-time Multiple Object Tracking
Abstract
文章认为MOT当前的主要挑战在于“不同帧中目标个数不定带来算法效率下降”。
- LSTM 只处理了single object。(也有处理多目标的)
Re-ID exhausitively 匹配目标表观。(这个不客观,大多数方法都会通过先验条件约束范围)
单个box处理耗时严重,因为需要crop+resize+extract features
文章针对该问题提出一种同时 关联不定数目目标的Deep Neural Network (DNN)
- Frame-wise Motion Fields (FMF) 估计目标运动位置,进行初步匹配。
- Frame-wise Apearance Features(FAF)针对于FMF失败情形,采用表观再次匹配
在MOT17 benchmark上保持SOTA性能同时,速度大幅提升。
Introduction
主要贡献点:
1) Frame-wise Motion Fields (FMF) to represent the association among indefinite number of objects between frames.
2) Frame-wise Apearance Feature (FAF) to provide Re-ID features to assist FMF-based object association.
3) A simple yet effective inference algorithm to link the objects according to FMFs, and to fix a few uncertain associations using FAFs.
4) Experiments on the challenging MOT17 benchmark show that our method achieves real-time MOT with competitive performance as the state-of-the-art approaches.
Proposed Method (FMA)
FMA方法网络结构如下图:
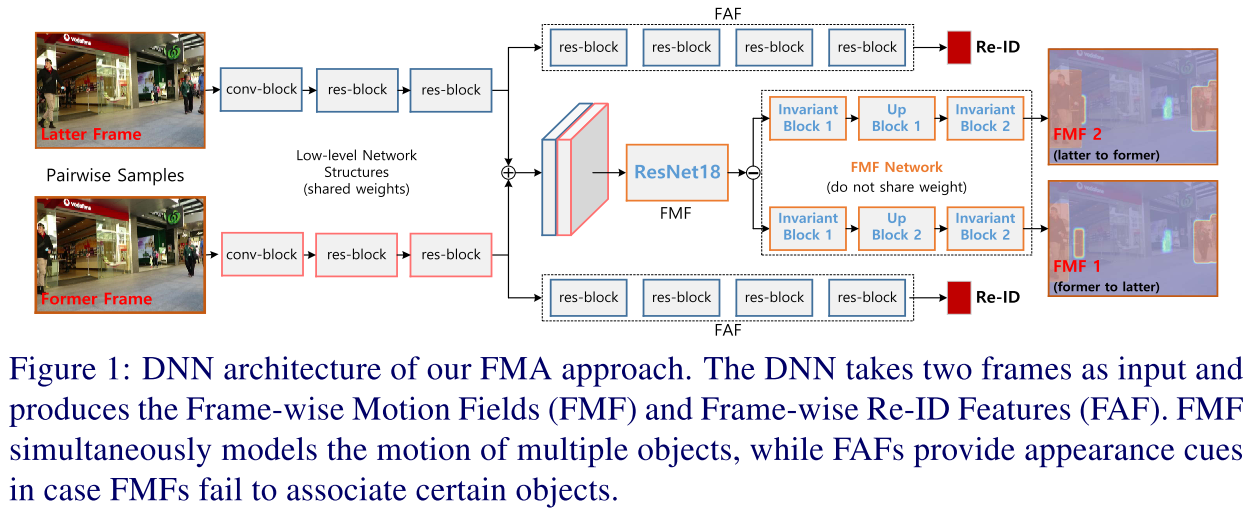
Frame-wise Motion Fields
使用$I_1, I_2\in R^{w\times h\times 3}$分别表示时间先后的两帧图像, $b_i$表示第$i$个关联目标的bounding box, 两帧中$b_i$的$x,y$坐标分别表示为$\mathcal{X}_1(b_i), \mathcal{Y}_1(b_i), \mathcal{X}_2(b_i), \mathcal{Y}_2(b_i)$ , FMFs计算了两帧图像$I_1, I_2$之间的四个运动场信息:
这里预测了目标的双向motion向量,主要是为了让motion向量更加鲁棒。两方面考虑: 1)前后两帧的表观和上下文信息可能差异较大,拆开考虑更鲁棒;2)可以解决部分遮挡问题,前后分别预测。示例如下图所示

注意上图(b)(d)中黑色十字标注的中心点.
损失函数:
$B$是关联的目标的bounding box的集合。
Frame-wise Appearance Features
FMF可以处理简单的情况,但是碰到拥挤或者干扰太多的时候就会预测失败,这时候希望通过FAF模块采用ReID实现匹配。
传统的ReID方法将每一个目标crop出来进行resize之后放到网络中抽取特征,耗时严重。该方法中利用FAF模块直接从整张图像中抽取每个目标的特征,同时FAF和FMF模块可以共享部分网络层。从而前向推理速度加快的同时也能够规避目标个数不同带来的问题。
给定同一个目标在两帧图像中的bounding boxes, FAF模块从FMF抽取的特征中crop patches,然后计算相似度。 在训练过程中同一个目标的不同特征concat一起作为正样本, 不同样本特征concat一起作为负样本。正负样本比例控制在$1:4$, 损失采用交叉熵损失
$p_j, \mathcal{S_j}$表示样本和对应label。
Inference Algorithm
$D=\{D_1, \cdots, D_N\}, T=\{T^1, \cdots, T^M\}$分别表示当前时刻的检测结果和已经存在的跟踪轨迹。 $IOU(\cdot)$表示IOU算子, $SIM(\cdot)$表示表观相似度。 Inference Algorithm分为3步:
- 从former 到latter进行关联
- 从latter 到former进行关联
- 关联失败剩下的tracks和detections,利用FAFs进行关联。
IOU和ReID的阈值分别为$\tau_1, \tau_2$
Experiments
Datasets: MOT17 benchmark
Setting:
训练样本对的选择: 两种时间间隔 每一帧和每4zhen
batchsize=4; lr=0.001, 70个epoch之后变为0.0001。
测试时样本对:连续两帧
$\tau_1=0.45, \tau_2=0.5$
Ablation Study
MOT result of each component

训练的使用同时训练FAF和FMF模块,然后使用每个模块进行跟踪。
性能差别不是很大,但速度差异明显。 作者认为FAF需要对图像进行crop因此速度较慢。
Effectiveness of FMFs
根据FMFs, 利用IOU初步匹配效果如下:这张图分辨率太低,根本得不到什么结论。

Comparison
性能对比
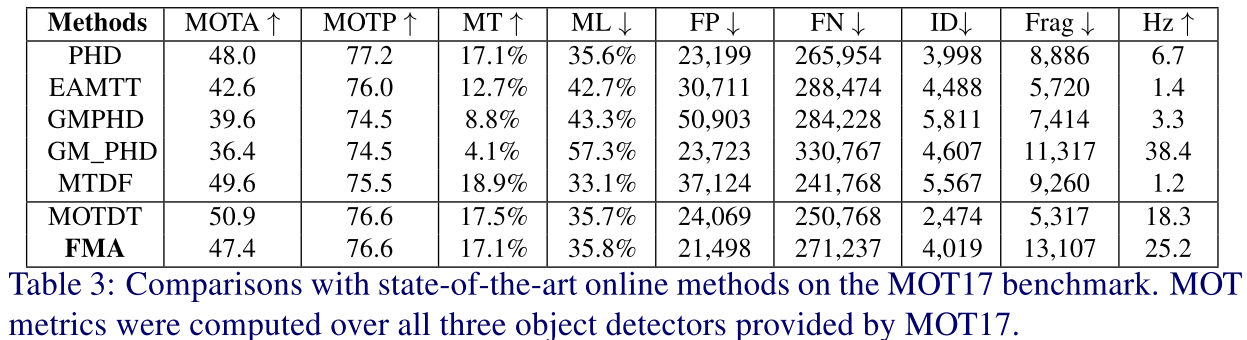
结论: a) 基于深度特征的方法性能优于传统特征; b)本文方法性能和MOTDT方法性能类似,但速度更快。
分析原因:a),训练数据太少,只在MOT17训练集上训练,b)该方法比较依赖于准确的检测结果
检测器对比
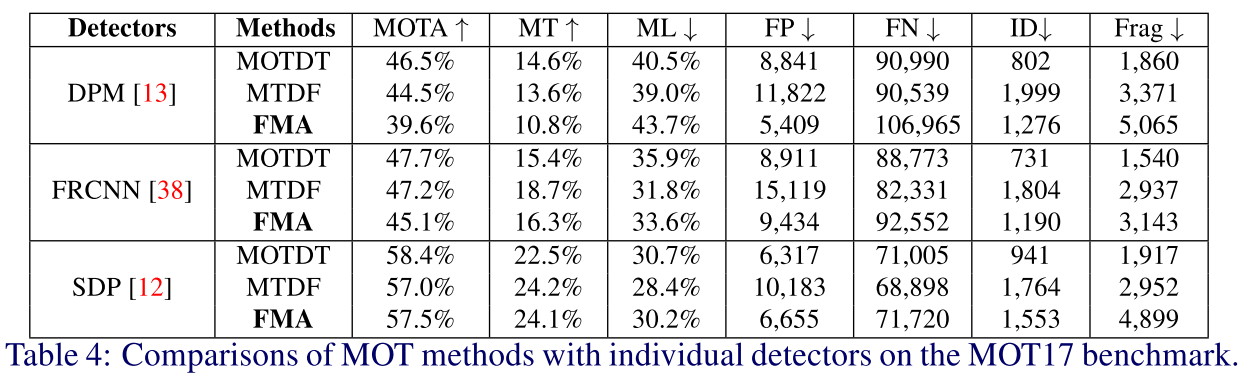
结论: 本文方法更适合于准确地检测器。
Conclusion
Practical and real-time MOT has to scale well with indefinite number of objects. This paper addresses this problem with frame-wise representations of object motion and appearance. In particular, FMFs simultaneously handle forward and backward motions of all bounding boxes in two input frames, which is the key to achieve real-time MOT inference. FAFs helps FMFs in handling some hard cases without significantly compromising the speed. The FMFs and FAFs are efficiently used in our inference algorithm, and achieved faster and more competitive results on the MOT17 benchmark. Our frame-wise representations are very efficient and general, making it possible to achieve real-time inference on more computationally expensive tracking tasks, such as instance segmentation tracking and scene mapping.
讨论
或许是因为preprint版本的原因,文章存在一些问题没有阐述明白。
- 计算FMF的时候样本点的个数太少,过于稀疏是如何训练的?
- 训练细节没有提供多少epoch等
- FAF进行crop时是从那一层crop的?
- 一般而言训练reid网络时,单独采用交叉熵损失似乎都不能取得较好效果。
本文作者 : zhouzongwei
原文链接 : http://yoursite.com/2019/05/17/Frame-wise-Motion-and-Appearance-for-Real-time-Multiple-Object-Tracking/
版权声明 : 本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明出处!
知识 & 情怀 | 赏或者不赏,我都在这,不声不响

