阅读笔记-MOT16:A Benchmark for Multi-Object Tracking
摘要
这篇文章主要介绍了MOT的2016 benchmark库。相对于MOT15的benchmark而言,MOT16 benchmark视频数据标注更加规范严格,除了标注pedestrian之外,还标注了其他部分类别,同时给出了每个标注的可见度。新的benchmark数据也更加多样。
Introduction
MOT15 benchmark存在的不足:
- 数据来源不同,标注协议也不完全相同。
- 测试集和训练集中人群密度分布不均衡。
- 部分训练集过于简单,不利用实际训练。如PETS09-S2L1.
- benchmark中提供的检测结果太差,导致跟踪IDs较高。
MOT16 benchmark的改进点:
- 14段视频数据,分别取自crowed scenarios, different viewpoints, camera motions 和 weather conditions, 训练数据足够复杂。
- 所有的序列均采用相同的标注协议进行标注。
- 除了pedestrian之外还标注了一些其他类别,提供训练。
MOT16 benchmark网站:
MOT16 datasets
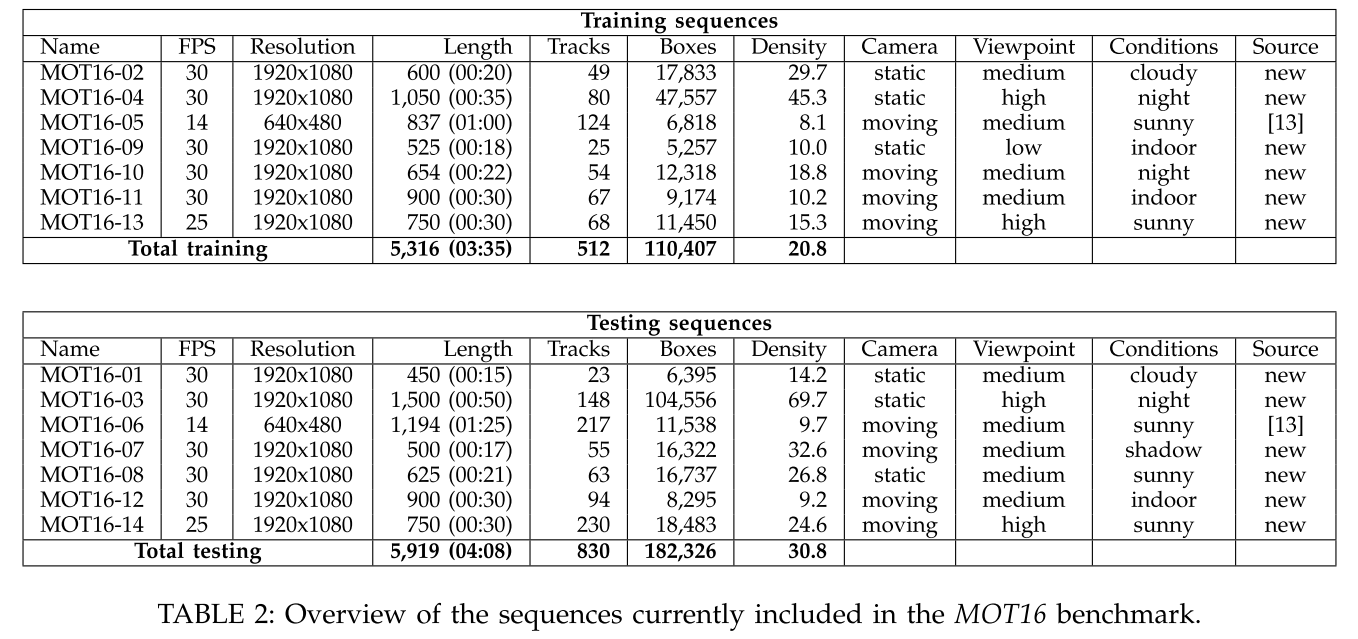
数据集overview

MOT16 benchmark 数据集示意。上面一行是训练集,下面一行是测试集。
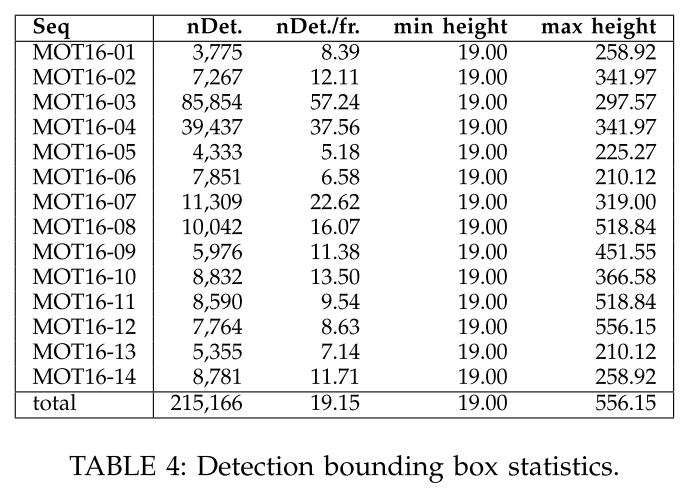
MOT16 benchmark 提供的检测结果
DPM检测结果。(另外,当前网站提供了FRCNN, SDP等多种检测结果)
detection 存储格式
示例
1
2
3
41, -1, 794.2, 47.5, 71.2, 174.8, 67.5, -1, -1
1, -1, 164.1, 19.6, 66.5, 163.2, 29.4, -1, -1
1, -1, 875.4, 39.9, 25.3, 145.0, 19.6, -1, -1
2, -1, 781.7, 25.1, 69.2, 170.2, 58.1, -1, -1det.txt文件的每一行存储一个box信息, 使用逗号隔开的9(实际是10)个数值表示。第一个数值表示box所在的帧号,第二个数值表示当前box对应的target id,对于detection而言,target id未知,都标注为-1;第三到六个值表示box的坐标,即(topleft_x, topleft_y, width, height),标注从1开始;第七个值表示detections的置信度, 剩下三个值占位,全为 $-1$ 。
MOT16 annotation
target class
MOT16 benchmark标注可以分为三类
(i) moving or standing pedestrians;
(ii) people that are not in an upright position or artificial representations of humans; and
(iii) vehicles and occluders.第一类的目标是希望跟踪的目标,包括所有的moving或者upright standing的行人,以及骑车或者滑板的也算。另外弯腰捡东西或者弯腰和孩童谈话的目标在评估时也会纳入考虑。
第二类目标没办法确切分类。比如非upright姿态的人,以及海报,倒影,镜像等,还用在玻璃之后的人都属于distractors。这类目标在评估时既不惩罚也不奖励,也就是说跟踪算法对这类数据的处理效果不影响最终评估性能。
第三类目标是各种车辆等遮挡物,这类目标在评估时也不考虑,标注的主要目的是提供额外信息用于估计遮挡程度等。
bounding box alignment
- box是目标的外接矩形框,所有的目标区域都在box内,所以对于行人而言,其宽度变化较剧烈。
- 对于遮挡目标,或者超出视野的目标,根据可见部分,估计整个目标的box。
- 如果遮挡的目标没法用一个box准确标注,那么可能用多个box标注。这主要针对于tree的大目标。
- 运输工具上的行人,只有充分可见时才会标注。比如汽车中的人不标注,自行车或者摩托上的人标注。
start and end of trajectories
- 轨迹尽可能的长。the annotation starts as early and ends as late as possible such that the accuracy is not forfeited
- 离开视野的目标再次出现时被赋予新的轨迹编号。
minimal size 和 occlusions
- 标注时对于size没有限制,多小的目标都会标注。
- 遮挡程度是计算出来的,不是显式指定的。
- 当目标被完全遮挡且不再可见时,认为该目标终止。
- 如果一个目标长时间遮挡后再次出现,但是位置变化很大,那么赋予新的轨迹id。
gt.txt存储格式和
det.txt类似,每一行存储10个数值表示当前box的跟踪结果。每个值的意义对应于下表
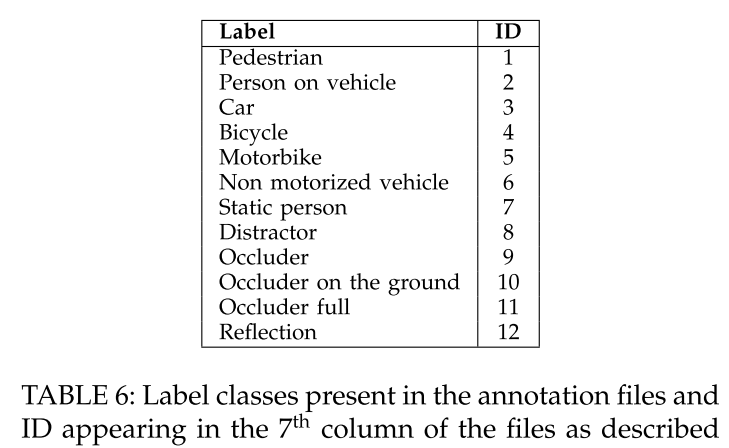
target所属类别编号如下:
MOT16 evaluation
tracker-to-target assignment
这部分主要包括指标FN, FP, FAF,用来评估检测目标和真实目标的匹配程度,注意,只是box的匹配程度,而没有考虑label是否一致
FN: False Negative, 所有的gt中没有匹配到检测的个数
FP: False Positive, 所有检测中没有匹配到gt的个数
FAF: the number of false alarms per frame, 也称为 FPPI: false positives per image
匹配的一致性
使用IDS指标,评估跟踪的一致性。IDS表示一条跟踪轨迹和真实轨迹在第$i$帧关联成功,但之前最近的时刻没有关联,则认为发生了一次ID switch。
值得注意的是, 检测和gt是否关联取决于两者之间的距离,比如IoU等,而当多个IoU符合条件时选择最大的IoU关联。但是在MOT中为了尽可能保持轨迹跟踪的一致性,如果$t-1$时刻truth object $i$ 和假设$j$ 匹配,但是$t$时刻虽然匹配,但不是最优匹配,这时候我们仍然选择$i,j$匹配。
为了让IDS与recovered targets无关,最终选择IDS/Recall度量一致性。
Distance measure
the intersection over union (a.k.a. the Jaccard index) is usually employed as the similarity criterion, while the threshold td is set to 0.5 or 50%.
Target-like annotations
计算evaluations之前,关联假设与gt的步骤:
1) At each frame, all bounding boxes of the result file are matched to the ground truth via the Hungarian algorithm. (使用匈牙利算法根据IoU关联)
2) All result boxes that overlap > 50% with one of these classes (distractor, static person, reflection, person on vehicle) are removed from the solution.(类似于NMS,先把distractor匹配的假设删除)
3) During the final evaluation, only those boxes that are annotated as pedestrians are used. (剩下的在计算性能)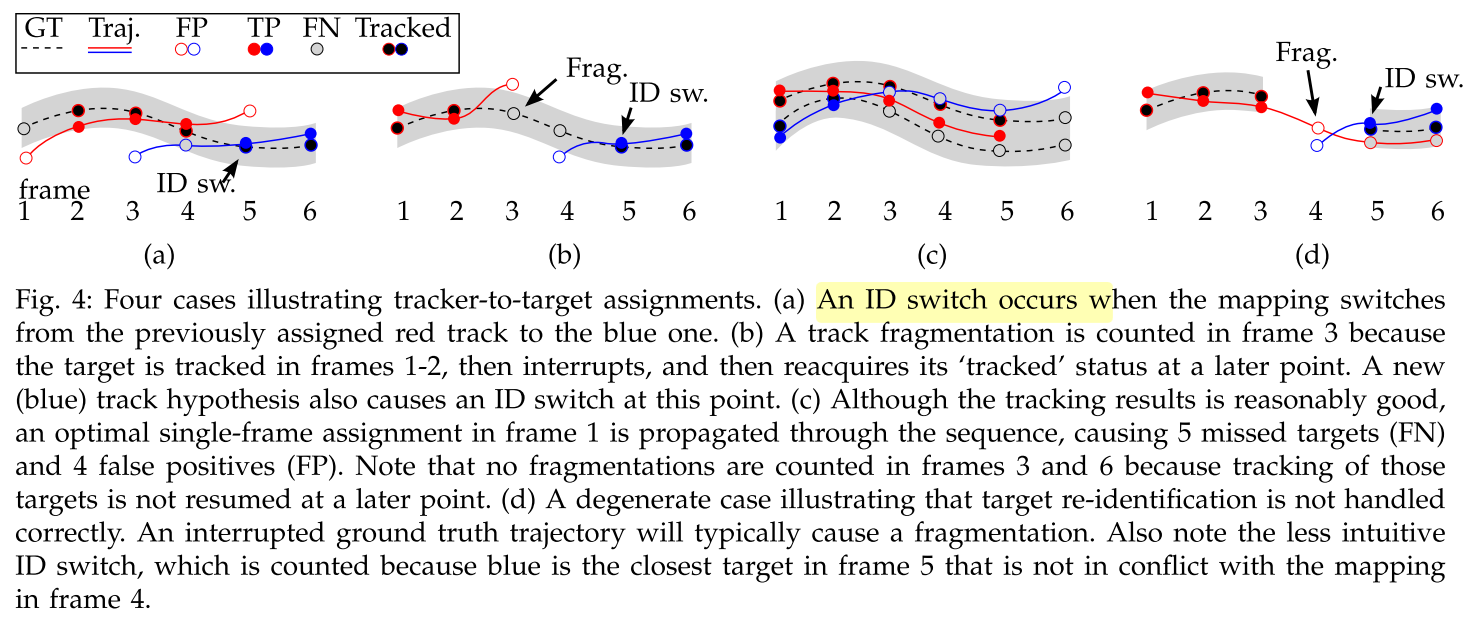
Multiple Object Tracking Accuracy
MOTA取值范围为$(-\infty, 100)$
Multiple Object Tracking Precision
MOTP取值范围$(50, 100)$。这里只计算匹配成功的平均匹配度,而匹配成功的阈值是$50$.
Track quality measures
- mostly tracked (MT): 至少$80\%$ 关联跟踪
- mostly lost (ML): 至少$80\%$关联失败
- partially tracked (PT): 少于$20\%$关联成功
注意我这里说关联,而没说跟踪是因为不论跟踪的trackid是否相同,只要gt匹配到假设就认为关联成功
MT, ML最终计算的是相对于ground truth trajectories的总数。
- track fragmentation(FM): 表示gt trajectory中的某个时刻没有关联成功,但前面存在关联成功,后续也关联成功,则认为是一次Frag,如上图中(b),(d)示意。与IDS类似,FM最终计算为FM/Recall
Baseline methods
这部分提供的baseline都太陈旧,性能很容易超越,所以需要新的baseline。
- DP_NMS
- CEM
- SMOT
- TBD
- JPDA_M
Conclusion
We have presented a new challenging set of sequences within the MOTChallenge benchmark. The 2016 sequences contain 3 times more targets to be tracked when compared to the initial 2015 version. Furthermore, more accurate annotations were carried out following a strict protocol, and extra classes such as vehicles, sitting people, reflections or distractors were also annotated to provide further information to the community. We believe that the MOT16 release within the already established MOTChallenge benchmark provides a fairer comparison of state-of-the-art tracking methods, and challenges researchers to develop more generic methods that perform well in unconstrained environments and on unseen data. In the future, we plan to continue our workshops and challenges series, and also introduce various other (sub-)benchmarks for targeted applications, e.g. sport analysis, or biomedical cell tracking.
本文作者 : zhouzongwei
原文链接 : http://yoursite.com/2019/05/17/MOT16-A-Benchmark-for-Multi-Object-Tracking/
版权声明 : 本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明出处!
知识 & 情怀 | 赏或者不赏,我都在这,不声不响

