阅读笔记-Spatial-Temporal Relation Networks for Multi-Object Tracking
Abstract
鲁棒的相似度度量是MOT取得较好性能的一个关键。而鲁棒的相似度度量应该能够变现表观、位置、时间和空间信息。由于这些线索差异性较大,不能直接组合在一起,一般的MOT方法会分别使用网络处理这些特征。
本文提出了一种Spatial-Temporal Relation network能够同时encode多种线索,并从时空关系中推理轨迹和检测的匹配关系。该网络能够端到端的训练并在MOT15-17benchmark上都取得了SOTA的性能。
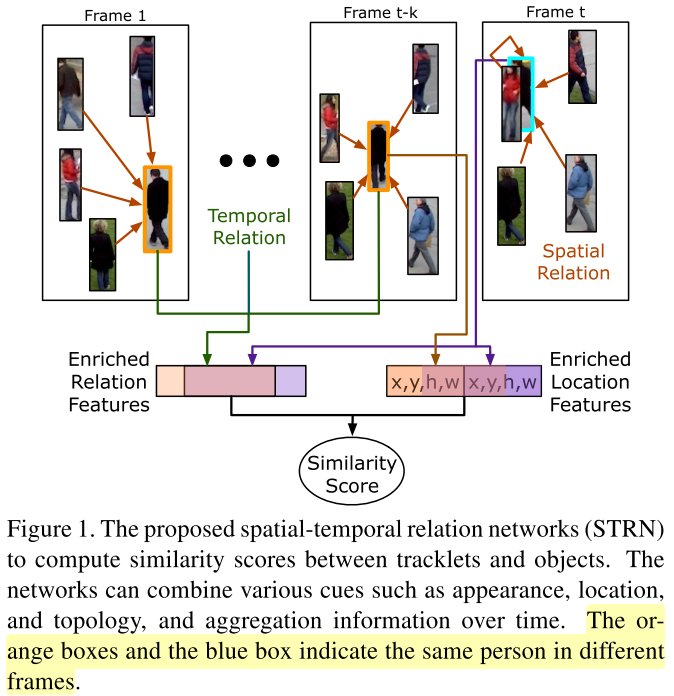
Introduction
相似度指标对于数据关联的影响很大。大多数方法都只利用表观计算相似度。这种方法有两点劣势。
- 像MOT benchmark这类数据集中,往往跟踪的目标来自于同一类,因此他们的表观很难区分,尤其是在比赛场景中,同队队员服装相同就更难区分。
- 多目标跟踪任务中经常出现遮挡比较严重,或者姿态变化较大的情况,都很难利用表观获得较好的匹配。
因此目前一些较好的方法也利用多线索融合的方式计算目标的相似度,比如表观,时间,空间等,代表性方法
A. Sadeghian, A. Alahi, and S. Savarese. Tracking the untrackable: Learning to track multiple cues with long-term dependencies. In ICCV2017, p300-311.
但是由于来自于不同线索的特征是异质的,不能简单的串接在一起,所以需要为每一个特征设计复杂的网络结果,上面那篇文章中分别使用LSTM刻画了表观特征,时间位置特征和空间拓扑特征。表观特征使用CNN抽取基本特征然后再放入到LSTM中计算检测与轨迹的相似特征向量, 时间位置特征类似,放入的是位置信息抽取特征向量,空间拓扑则是在每一个目标周围选取grid区域,然后将临近点的2D分布送入LSTM中抽取空间特征,最后再将三种特征并在一起进行相似度度量学习。
这篇文章提出了一个统一框架用于融合多线索进行相似性度量。其主要思想是在空间和时间上同时利用relation network刻画目标之间关系,包括位置和表观。
如Figure 1.所示, 现在每一帧中利用关系网络进一步strengthen 每一个目标的表观特征,然后再与存在的tracklets的strengthen的表观特征利用时域的关系网络进行串联并学习相似度。
Method
Notation
$\{T_i\}_{i=1}^N$ 表示$N$条轨迹
$T_i=\{b_i^t\}_{t=1}^T$ 表示第$i$条轨迹中的$T$帧中匹配到的位置, bounding box。
$b_i^t = [x_i^t, y_i^t, w_i^t, h_i^t]$ 中心点的坐标和目标的宽度与高度
$D_t=\{b_j^t\}_{j=1}^{N_t}$ 时刻$t$中的所有检测响应
跟踪流程
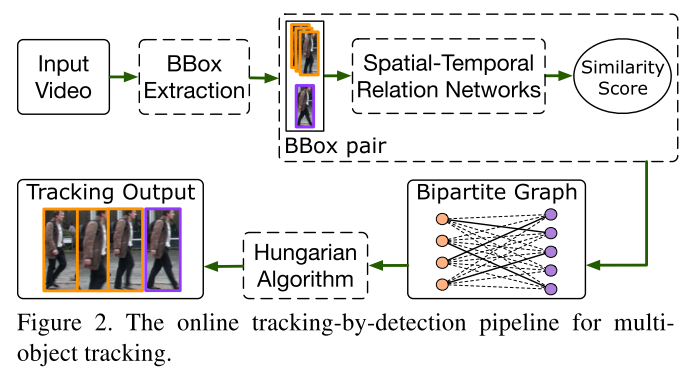
本文方法依然在tracking-by-detection框架下,因此给定图像序列,首先使用检测器对目标进行检测。然后将以跟踪的轨迹与当前帧的检测配对放入到Spatial-Temporal Relation Networks (STRN)中计算每一个点对的相似度。于是轨迹和检测就行了二部图,采用匈牙利算法进行数据关联将检测分配给不同的轨迹。
Spatial-Temporal Relation Networks的框架如下图所示:
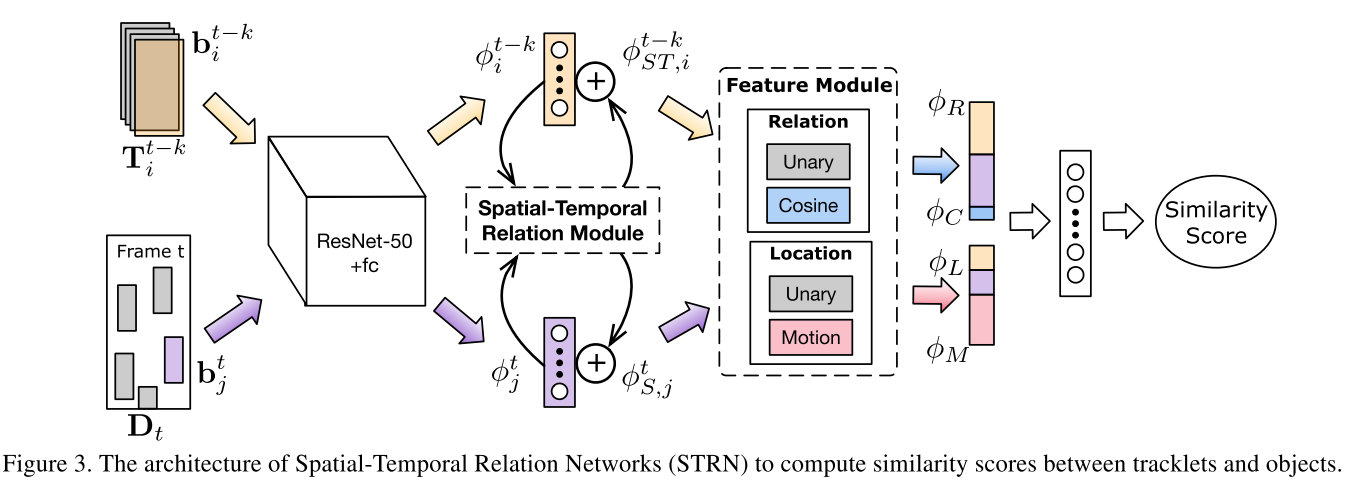
首先采用ResNet50网络提取当前帧中检测的特征以及历史轨迹中每个目标的特征,然后分别计算每个目标在关系网络中的特征和每条轨迹在时域中加权的特征,分别记为$\phi_{s,j}^t, \phi_{ST, i}^{t-k}$ , 然后将特征进行配对,送入到feature module中计算四种embedded特征,再将四种特征concat成最终特征用于计算相似度. 下面分别介绍spatial-temporal relation module和feature module。
spatial-temporal relation module
- 空域的object relation module (ORM)
这部分的内容应该是受下面这篇文章的启发,利用GCN网络进行目标检测
H. Hu, J. Gu, Z. Zhang, J. Dai, and Y. Wei. Relation networks for object detection. 2018.
每一个目标可以使用$o_i = (\phi_i, b_i)$表示,分别表示表观特征和位置信息。那么refined 特征相当于GCN网络抽取的特征。
$j$取同一帧中所有目标, 所以上式表示新的特征等于本身特征和其他目标的影响的结合。$W_V$是学习参数,表示对特征的进一步抽象。$w_ij$表示$j$样本对当前$i$样本的贡献量,是一种attention权重。
$w_{ij}^A$表示的是projected后的表观特征的scaled的内积。这个scale主要是让attention更加平稳。
$W_Q, W_K$分别表示project矩阵, $d$表示投影特征的维度, $w_{ij}^G$表示的是相对位置关系。$w_{ij}^G = \log\big( \frac{|x_i-x_j|}{w_j}, \frac{|y_i-y_j}{h_j}, \frac{w_i}{w_j}, \frac{h_i}{h_j}\big )$
- 时域的关系网络
时域的关系网络可直接通过节点域有单帧图像扩大到多帧图像处理,但这种方式存在两个缺陷。
首先,计算量急剧增大;其次,空间特征和时间特征本质上是不同的信息。
所以,这这篇文章中的时域关系网络本质上是时域上的attention机制,即加权平均值。
空间关系网络输出特征表示为$\phi_{S,i}$ 时间关系网络在空间关系网络的输出特征上进行操作。
这里值得注意的是,计算时间关系特征的时候只计算轨迹的特征,而当前帧中的检测不参与计算。
$w_T$是待学习参数。


Feature representation
这个模块主要用于集成不同的线索,最终计算相似度。
下面介绍四种特征$\phi_R, \phi_C, \phi_L, \phi_M$.
Relation features
最直接的方式是将每个待关联的轨迹最后一帧的特征和待检测目标的特征串联起来作为新的特征然后将新的特征送入网络进一步抽象。
作者认为这个特征是把双刃剑,既可以直接用来计算相似度,也给学习紧致的目标特征带来了难度。因此作者又在关系特征$\phi_{ST,i}^{t-k}, \phi_{S,j}^t$上直接显示的计算了余弦相似度。
分析:
In general, cosine value could take effect only in the scenarios where two input features are compatible in representation.
即一般而言,cosine距离最好直接度量来自于相同空间向量的相似度,但这里的特征来自于检测和轨迹。看起来似乎不同空间。但是经过分析可以发现轨迹的特征其实是在时间域上的加权平均值,而每一个元素都是每帧图像检测的空间特征,因此特,他们其实分布在临近空间,所以可以使用cosine距离刻画。
location features
位置关系和运动信息是另外两种常用的匹配信息。文章选择每个跟踪轨迹的最后出现目标的位置的大小作为参考目标,embedding 当前检测的位置和大小信息。
其中$*\in \{L, M\}$分别表示位置和运动信息。
位置信息是4维特征。
其中$I_w^t, I_h^t$表示第$t$帧图像的宽和高。 $f_L(b_i^{t-k}, b_j^t) = [f_L’(b_i^{t-k}); f_L’(b_j^t)]$
运动信息则是刻画的目标之间的相互位置和大小关系。
这部分我觉得设计存在一定问题。前面两项都是计算的变化速度,但后面两项其实不应该计算相对比例的变化速度,直接使用比值,或者平均差值或者会更好
Experiments
Datasets and Evaluation Metrics
dataset: 2D MOT2015, MOT16, MOT17
metrics: CLEAR and IDF1 Score
Implementation Details
- backbone network是在ImageNet预训练的ResNet50网络, 并在MOT训练集上finetune
- 每个目标是经过crop之后再rescale到$128\times 64$之后放入特征抽取网络。
- 计算temporal relation时使用了最近的$9$帧图像。
- 网络的其他参数见原文。
跟踪器参数
若视频序列的帧率为$F$, 如果一条轨迹在初始化之后的$F$帧内匹配成功的次数低于$0.3F$则认为是错误的初始化,剔除。
当轨迹在最近的$1.25F$内都没出现成功匹配则认为该轨迹结束。
Ablation Study
分解实验是在MOT15上进行的。
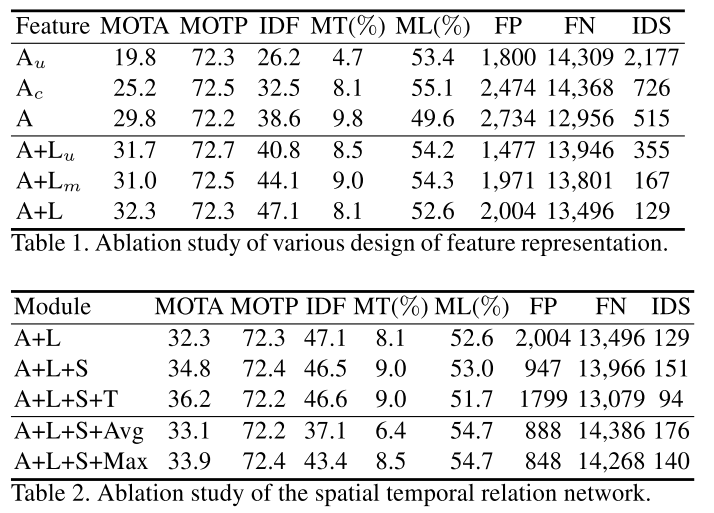
Table 1的上三行 表示没有使用关系网络的性能。$A_u$表示只利用resnet50抽取的特征学习相似度,这部分其实是一种度量学习的方式。$A_c$表示只计算cosine距离而没有利用unary appearance, 这部分则相当于feature embedding的过程,$A$则是同时利用了两种信息,可以发现两种信息都利用的效果最好。
Table1 的下三行表示结合了location特征的性能, $L_u$表示仅利用了位置信息, $L_m$表示仅利用运动信息,可以发现两种location特征融合时,性能最好。同时加入位置信息相对于仅利用表观表观信息性能得到很大提升。这主要归功于IDS的下降。
Table 2 上三行对比了时间和空间关系网络对性能的影响。可以发现单独加入spatial 关系网络,性能既有较大提升,但是此时IDS反而变大了。FP的降低表明空间关系网络对检测是有用的,但是可能由于目标特征的融合会导致部分较近目标难以区分,从而导致IDS增大。 而加上时间attention之后性能进一步提升,表明时间上的attention能够更好的刻画历史信息。此时IDS下降。
Table 2 下两行是将时间attention机制之间用池化方式去做,发现性能下降了,当然相对于baseline还是有所提升的,证明temporal 信息有助于跟踪,但attention主动调整权重的方式比预设的均值或者最大值方式更加有效。
MOT Benchmarks
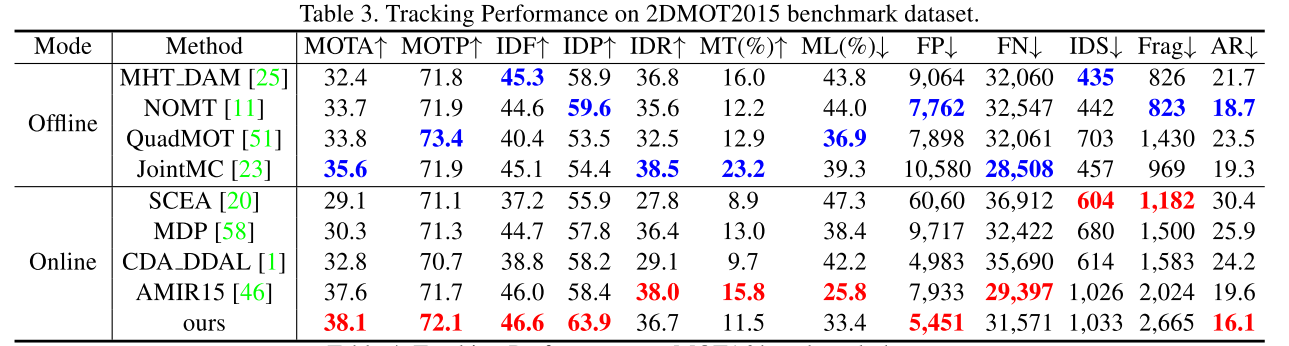
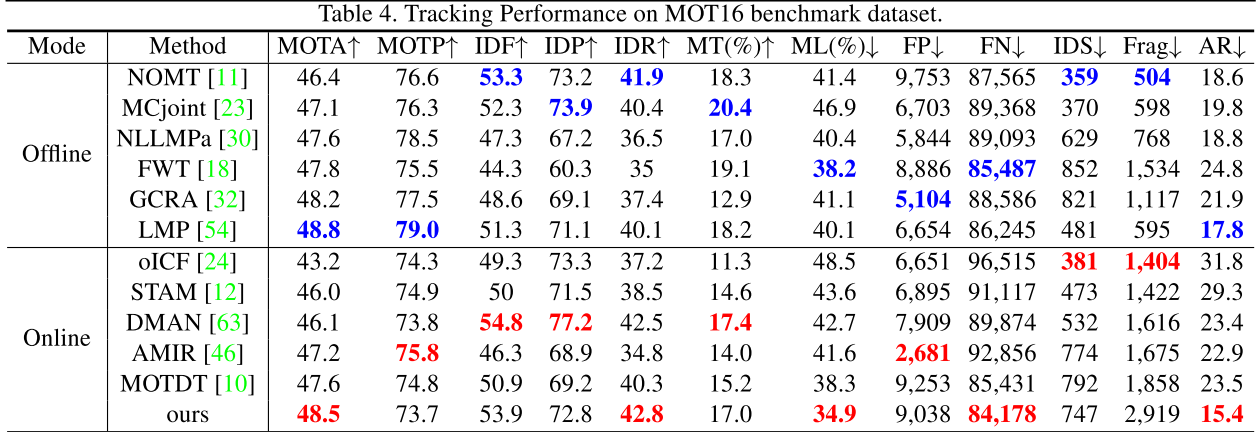
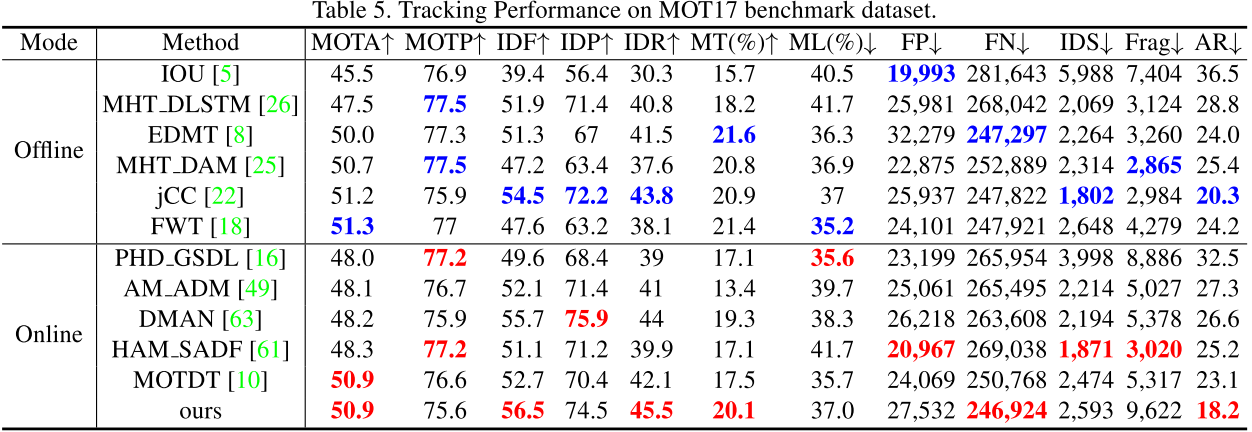
实验证明了方法的有效性,但其实这篇文章对比的baseline目前性能并不是最好的。只能说该方法性能还不错。
Conclusion
该文章STRN说是提出了一种时空关系网络同时处理多种线索,其本质上空间关系利用的是gcn的思想,时间上利用的attention的思想,然后再将位置信息与表观信息融合来进行度量学习。
本文作者 : zhouzongwei
原文链接 : http://yoursite.com/2019/05/19/STRN/
版权声明 : 本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明出处!
知识 & 情怀 | 赏或者不赏,我都在这,不声不响

