多目标跟踪总结(中)-深度方法
导言
随着深度学习的推进,基于深度学习的检测器性能提升明显。因此目前的多目标跟踪算法大都基于tracking-by-detection框架。于是MOT任务可以转化为detection+ReID问题。
但相对于与传统的ReID问题,MOT问题会更加复杂。首先,MOT任务中目标轨迹变化频繁, 图像样本库的数量和种类都不固定; 其次,检测结果可能出现新的目标,也可能出现漏检;另外,检测图像并不像行人重识别中的查询图像都是比较准确地检测结果, MOT任务中行人检测往往混杂着误检或者不准确的检测,尤其是相互遮挡产生时。检测行人的不对齐,相互遮挡给目标匹配带来了极大的挑战性。
本文将主要总结一些基于深度网络,希望更好解决MOT任务中ReID子任务的方法。
基于深度学习的多目标跟踪算法分类
基于深度学习的多目标跟踪算法的主要任务是优化检测之间相似性或距离度量的设计。根据 学习特征的不同,基于深度学习的多目标跟踪可以分为表观特征的深度学习,基于相似性度 量的深度学习,以及基于高阶匹配特征的深度学习。
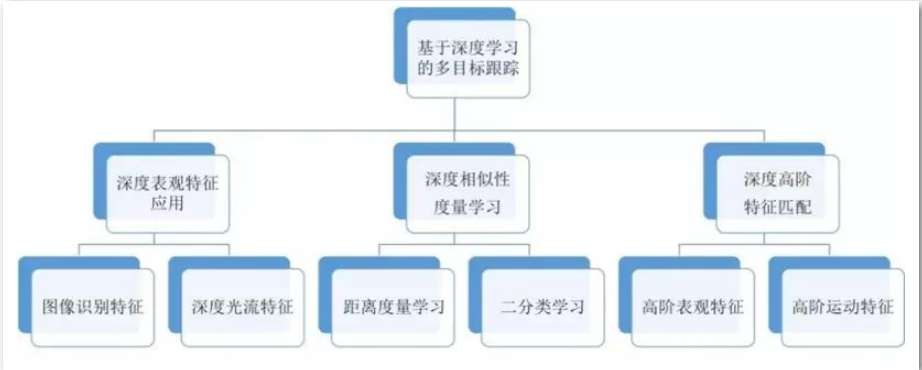
- 利用深度网络学习目标检测的表观鉴别特征能有效提升匹配跟踪性能。比如利用图像识别或者行人重识别中的特征抽取网络替换MOT框架中的hand-craft表观特征,或者基于深度网络的光流特征计算运动相关性。
- 利用深度学习方法进行度量学习。比如设计网络计算检测和轨迹的距离函数,或者设计二分类代价函数,判断目标是否属于同一类。
- 基于深度网络学习高阶特征。比如考虑以跟踪轨迹和检测之间的匹配或者tracklets之间的匹配等。深度网络学习高阶特征匹配可以学习多帧表观特征的高阶匹配相似性,也可以学习运动特征的匹配相关度。
深度视觉多目标跟踪算法介绍
基于Siamese网络结构的跟踪算法
该类方法以两个经crop之后尺寸相同的检测图像块作为输入,输出的是二分类判别是否属于同一类。 一般Siamese结构有三种形式。如下所示:
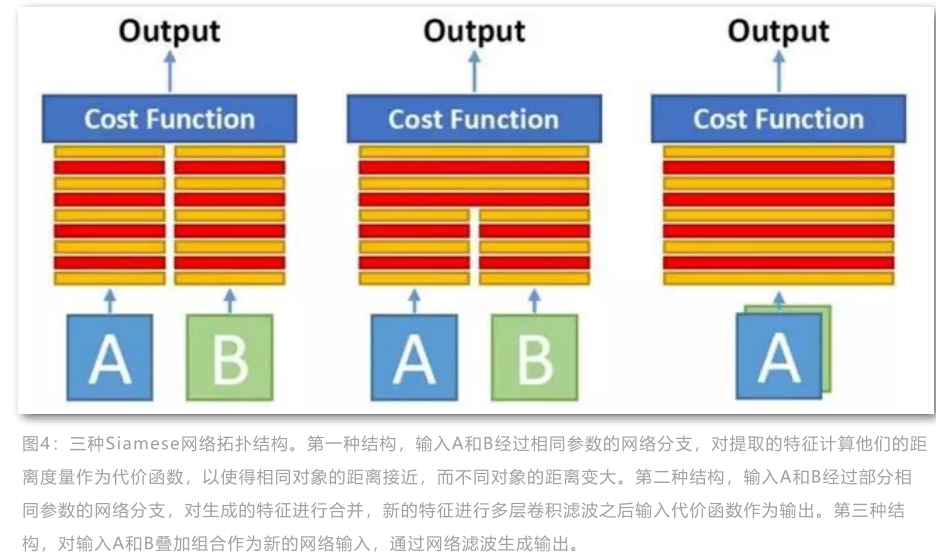
一般而言第一种方式属于特征学习,第二三两种属于度量学习。实验表明,第三种拓扑结构能够生成更好地实验效果。所以Lealtaixe等人采用第三种形式结构计算检测之间的匹配度。原始的检测经过预处理成对和光流对的输入网络中。这些预处理包括正则化LUV空间,resize到固定大小$121\times 53$等。
网络的输入层通道数为$10$, 后面跟有$3$个卷积层,$4$个全连接层和binary-softmax损失层。损失函数为
训练过程中,从真实跟踪数据中抽取训练样本。利用检测算法得到的同一条轨迹的检测作为正样本,不同轨迹的检测作为负样本,为了增加样本多样性,增强模型的泛化能力, 负样本还包括从检测响应周围随机采集的重叠率较小的图像块。训练细节:SGD优化器, bs=128, lr=0.01, num_epoches=50
在孪生网络训练完成后, 作者采用第六层全连接网络的输出作为表观特征,然后通过gradient boosting算法融合目标的上下文信息,包括:尺寸相对变化、位置相对变化和速度相对变化。其结构图如下所示:
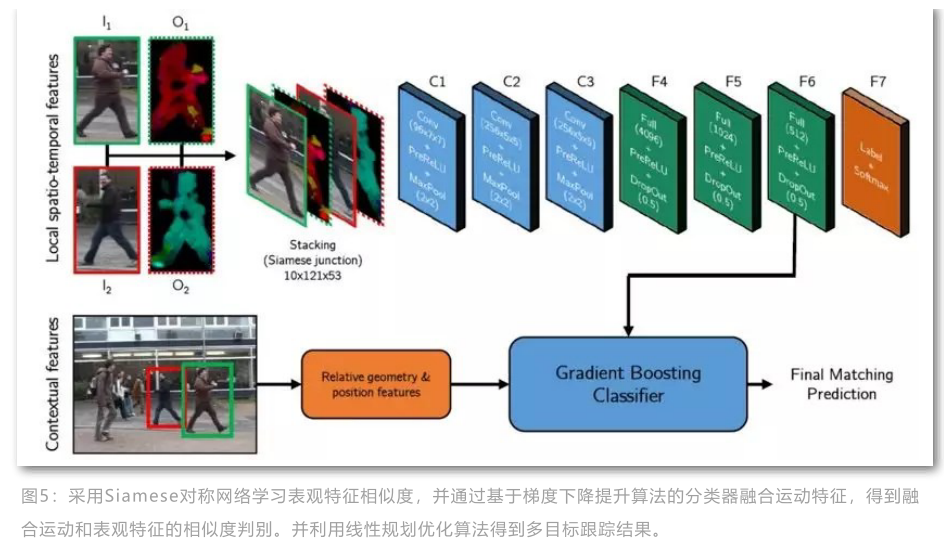
多目标跟踪过程采用全局最优算法框架,通过对任意两个检测建立连接关系,生成匹配矩阵,采用最小代价网络流的方式转化为线性规划进行求解。
基于最小多个图模型的多目标跟踪算法
Siyu Tang等人利用深度学习计算的类似光流特征结合子图多割模型在MOT任务上取得了很好的效果。
该方法属于离线确定性推导方法。作者认为对于检测响应的处理,例如NMS过于粗糙,会导致有些正确的检测被抑制掉,同时同一帧图像中检测之间的关系也没有考虑。于是作者剔除了MOT任务中的一般假设:一条轨迹最多对应一个检测,同样一个检测最多对应一条轨迹。使用多帧之间的所有检测响应构建图模型,并提出子图划分的算法进行求解轨迹。
如下图所示, 每一个顶点对应一个检测响应,不同的颜色对应不同的目标响应,相同颜色对应相同目标的不同检测响应。
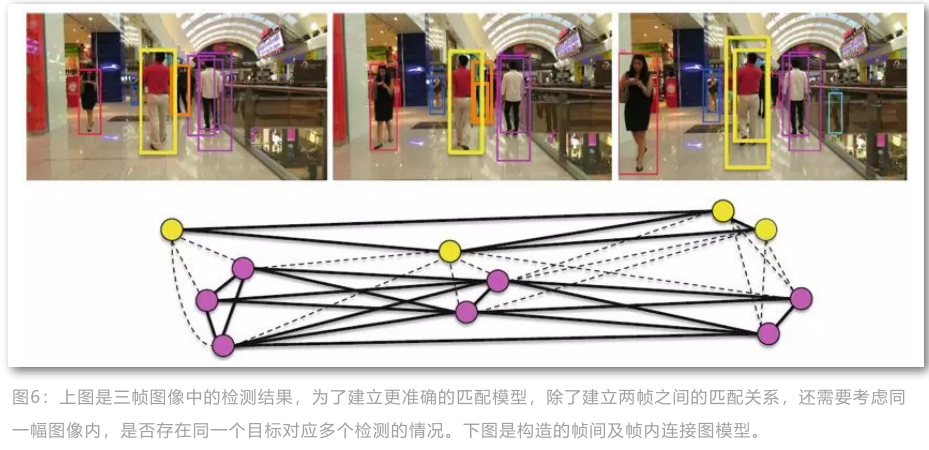
子图多割的模型:
其中$c_e$表示每条边的代价, $x_e$表示每条边是否关联的示性变量, 约束条件表示对于图$G$中任意的环路$cycles(G)$之一$C$,任意两点如果存在一条通路,即不等式右边为0, 那么这两点之间必定相同,即$x_e=0$.也就是说一个环路中若存在分割边,那么至少存在两条,于是环路就可以分割成不同的图,代表不同的轨迹。该模型可以使用KLj算法求解。
在计算检测之间的关联关系时,作者利用deepmatching光流方法构建了$5$维特征。
MI, MU分别表示对应响应中光流点集的交集和并集的基数比, $\varepsilon_v, \varepsilon_w$分别表示置信度。 利用5维特征学习逻辑回归分类器用于计算两者属于相同目标的概率$p_e$, 注意这里的训练是在训练集上利用特征学习回归分类器,而计算匹配概率$p_e$时则是在推断阶段。获得了匹配概率$p_e$其实已经可以采用匈牙利算法等进行匹配,但是为了实现本文的motivation, 计算(2)式中的代价$c_e=\frac{p_e}{1-p_E}$, 进而更好地计算匹配关联。
为了更好地利用长时信息,已解决遮挡或者错误关联问题,作者又在子图多割基础上提出了提升边的改进。其基本思想是将图中的连接边进一步划分为常规边和提升边,分别用来刻画短期和长期匹配关系。
示例
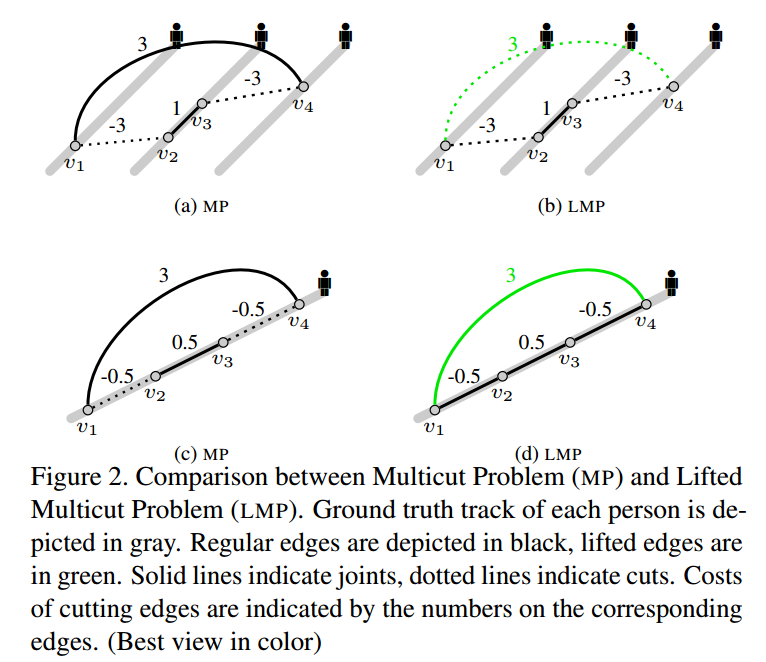
在子图(a),(b)中有3条真实轨迹, $v_1$对应$t$时刻的一个目标, $v_2, v_3$对应$t, t+1$时刻的同一个目标, $v_4$对应$t+1$时刻的新目标, 每条轨迹的代价如图所示,因此采用MP方法,则将$v_1v_2, v_3v_4$切断,这样就会导致$v_1, v_4$划分为一类,发生错误匹配。而对于LMP, $v_1v_4$属于提升边,提升边另外考虑,因此并不会分错。同理的是图(c)(d), 同一个目标可能因为遮挡或者光照原因,中间若干帧发生表观变化,这时候采用MP算法会导致跟踪片段, 而采用提升边方法可以有效避免这种现象。
提升边的子图多割相对于子图多割方法额外增加了两条约束
这里$E$ 表示时间空间约束的常规边, $E’$则是常规边和提升边的合集, 提升边是指时间间隔大于某阈值,而表观非常相似的检测之间的关联。上述约束表示对于任意的两个顶点$v,w$其中存在的提升边$vw$和任意的通路$P$,那么如果常规边是连通的则提升边必定连通。
$vw-cuts(G)$表示节点$v,w$之间所有可能存在切边的路径, 于是可以知道,如果$vw$之间不存在任何通路,则提升边必定是切边。
目标函数和MP的目标函数相同,不同的是MP构造了5维特征, 而LMP则是利用siamese结构网络提取表观特征再与MP中特征结合构建目标函数。
siamese结构的表观相似度网络

LMP算法目前在MOT16benchmark上的性能依然算是SOTA。
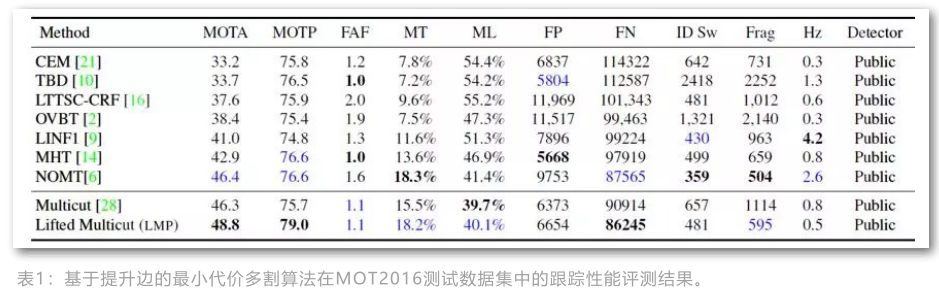
时空注意力机制的多目标跟踪(STAM)
该方法借助注意力机制处理多目标跟踪中目标遮挡问题, 并对每一个目标建立单独的分类器,判断检测和轨迹是否匹配,其本质上是单目标跟踪算法在多目标任务上的扩展。其流程图如下:
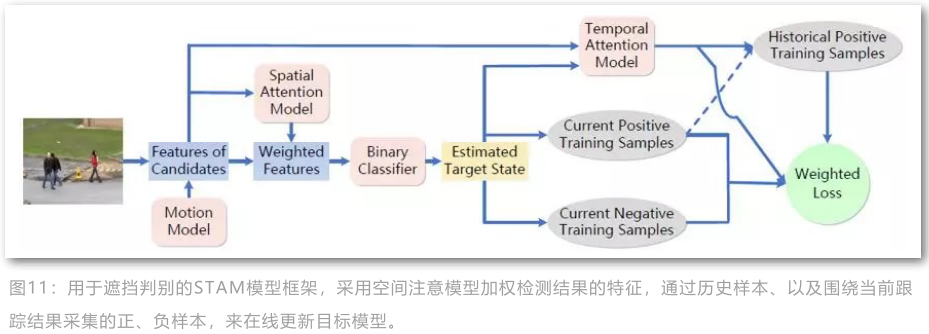
空间注意力机制用于给不同程度的遮挡部分不同的特征权重,从而能够更好地抽取可鉴别特征, 时间注意力机制则主要是给历史样本不同的权重用于在线更新模型。
空间注意力模型如下图中(b)所示,对于经过ROIPooling之后的对齐特征学习其每个空间位置的权重,由于训练样本不足,直接学习spatial attention map比较困难,因此作者采用了分阶段的思想。
首先希望能够回归出目标的visibility map,这部分可以提供额外的标签信息,因此学习起来相对简单,然后再有visibility map学习spatial attention map. 获得spatial attention map之后采用乘性方式叠加到池化特征上获得refined feature maps,然后从该特征训练二值分类器。
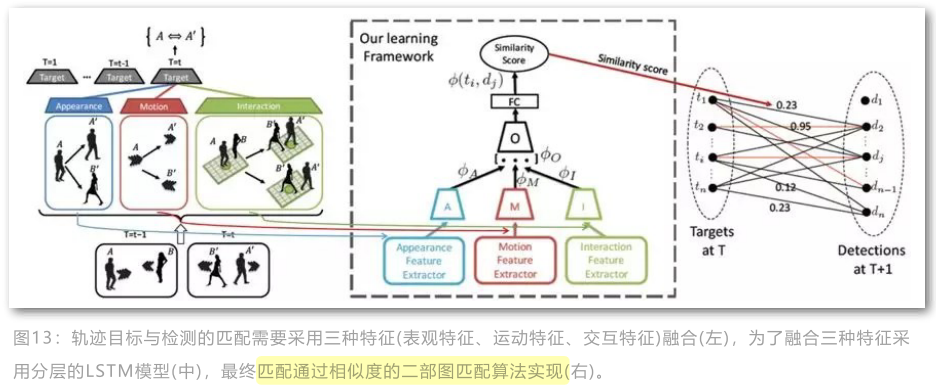
基于LSTM的多线索融合多目标跟踪
前面叙述的方法很少利用时间上的性质,即使用到的话也是简单的attention机制提供权重, 而这篇文章则直接将LSTM网络应用到MOT的时序信息上,并同时融合了时序,表观,空间等线索用于多目标跟踪。
其基本流程如下所示,使用lstm分别刻画提取appearance, motion和interaction的相似特征。然后通过在线方式将三种不同的特征融合起来进行度量学习,最后有学习的度量计算相似度,构建二部图再进行数据关联。
基于LSTM的表观特征
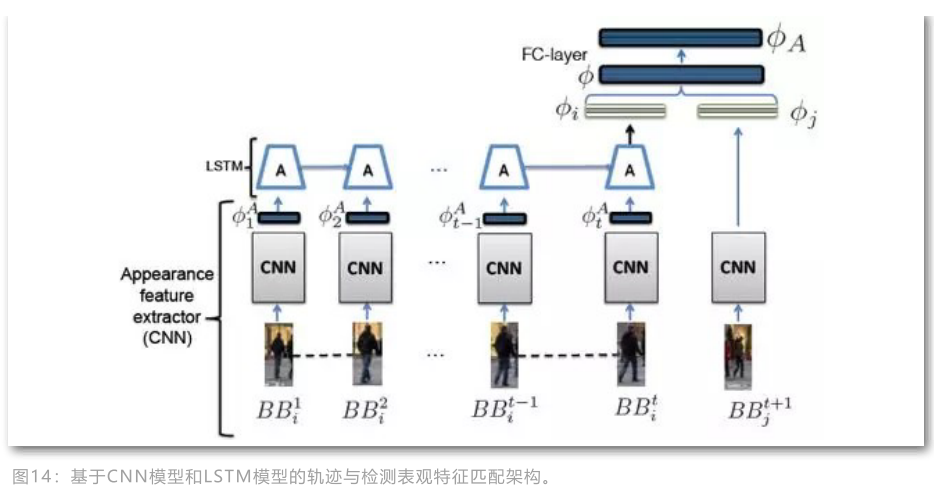
输入是crop和resize只有的每个目标,lstm用于抽取已获得轨迹在最后时刻的特征, 然后将lstm特征和当前待匹配的检测响应的特征输入到siamese的浅层网络中融合特征。
基于LSTM的运动特征
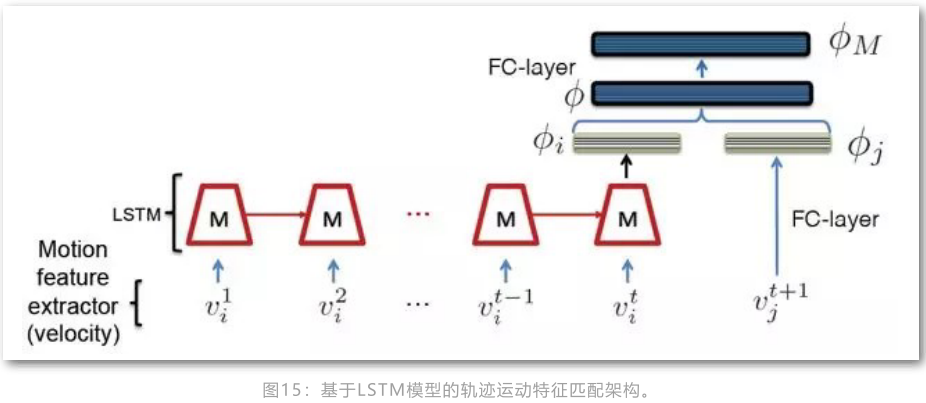
基于lstm的motion特征和appearance特征网络相似,不同点在于motio输入的是历史跟踪结果的瞬时速度信息,而appearance输入的经过CNN抽取的表观特征。
基于LSTM的空间特征
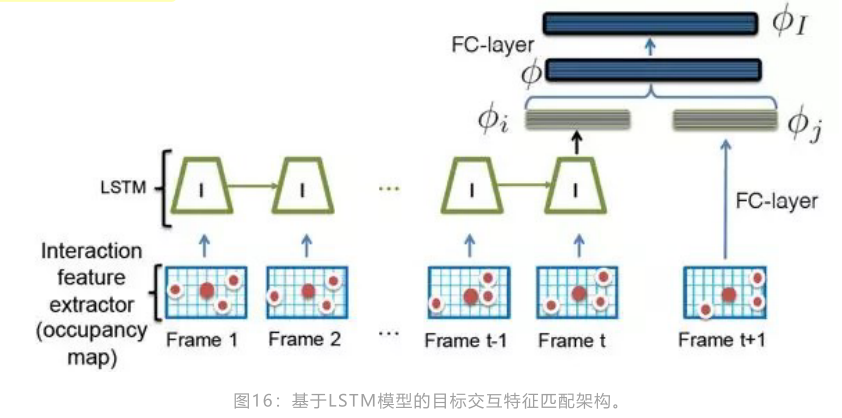
值得一提的是,基于LSTM的interaction特征,输入是2D拓扑图,刻画的是目标的spatial context。将目标的邻域范围划分网格,然后有目标的网格则置为1,否则置为0.这种做法具有一定的刻画空间上下文的能力,但其实相当粗暴。
基于双线性LSTM的多目标跟踪
Kim等人在基于LSTM融合特征的多目标跟踪算法基础上提出了基于双线性LSTM的多目标跟踪方法。
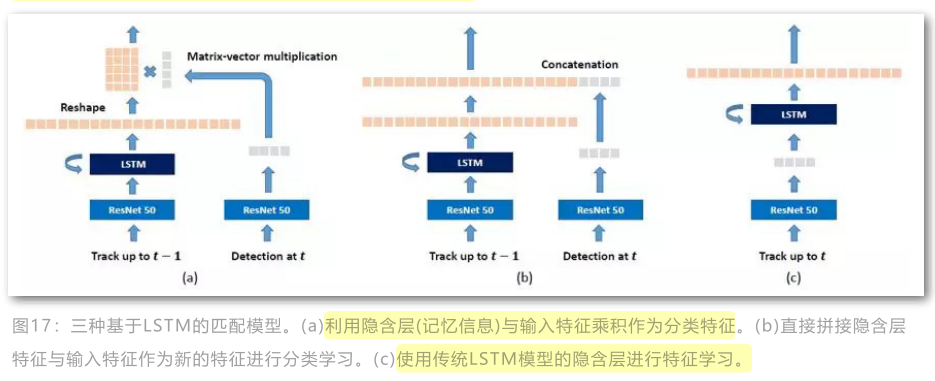
图中(a)图示双线性LSTM的结构图,其区别在于将lstm提取的特征与检测响应的特征进行了乘性相关运算从而更好地计算相似度。
作者发现使用提出的基于双线性的LSTM结构能更好地刻画表观特征,但对于motion特征不如直接基于lstm的结构(这可能是因为LSTM目前对高维特征的刻画不够准确),所以最终融合两种方式在MHT框架下提出了MHT-bLSTM算法,其性能如下
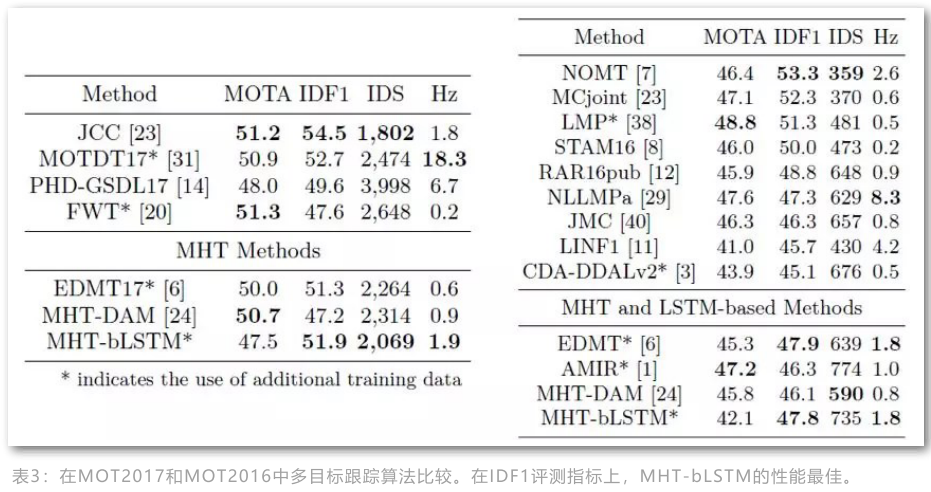
可以发现本文方法其实MOTA性能并不是很好,其提升点主要在于IDF1指标,说明其对于保持跟踪的稳定具有不错的效果。
Conclusion
近些年多目标跟踪领域的深度学习方法更多的集中在深度特征和深度度量的学习,很少有采用深度学习解决目标之间数据关联的工作,最近又一篇deep match 的文章值得关注,后续我们继续解读。
我认为目标跟踪未来的发展趋势应该集中于两点:首先如何确定轨迹的起点和终点,这部分目前存在一些利用强化学习处理的工作;其次如何直接使用深度学习的方式解决数据关联问题,这部分应该可以从图卷积网络入手。
除了上面的发展趋势,我认为目标CNN或者LSTM框架下的研究方向也包括两点:首先是继续提升目标检测的精度,尤其是遮挡环境,精确地目标检测结果对于目标跟踪影响很大;其次是如何解决遮挡导致跟踪失败的问题。
参考[SIGAI]公众号, 
本文作者 : zhouzongwei
原文链接 : http://yoursite.com/2019/05/20/MOT-overview-2nd/
版权声明 : 本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明出处!
知识 & 情怀 | 赏或者不赏,我都在这,不声不响

