阅读笔记-Repulsion loss:Detecting Pedestrians in a Crowd
Abstract
尽管目标检测目前已经取得了非常好的性能,但是针对于特定领域内的跟踪方法还可以进一步探讨。本篇文章的研究重点在于更好的检测拥挤场景下的行人。
文章首先分析了拥挤场景下SOTA检测方法存在的问题,然后提出了一种针对于拥挤场景专门设计的回归损失。该损失函数的启发源主要有两点:预测框应该尽可能和目标接近;同时预测框应尽可能地与surrounding目标区分。
实验证明本文提出的损失函数能够在拥挤场景中很大提升SOTA方法的性能。
Introduction
一般情形下,遮挡可以分为两种: 类间遮挡(inter-class occlusion)和类内遮挡(intra-class occlusion). 在行人检测任务上, inter-class occlusion例如行人被汽车,树木等他类遮挡;intra-class occlusion 如人与人之间的遮挡。
crowd occlusion对行人检测的影响主要体现在增加了pedestrian定位的难度。例如两个目标$T,B$发生了遮挡, 那么检测器就会因为这两个target overlap部分的特征相同而出现较大的误差。导致$T$的预测窗口可能更偏向于$B$ 或者相反。更糟糕的是,一般detection之后的结果需要进行NMS操作,NMS操作可能凭IOU将发生shift的预测框直接剔除,导致miss detection的产生。所以crowd occlusion环境对于NMS的阈值较敏感。 阈值较高剔除的框越少可能产生的false positive越多, 阈值较小剔除较多导致miss detections很多。
传统的检测方法使用box regression技术localized 目标,具体而言就是让proposals和ground-truth之间的距离尽可能地接近,距离度量可以使用$\text{Smooth}_{L1}$ 或者IoU等。但是这种约束只是让predict尽可能地和target接近,而并没有考虑到target周围的影响。如下图所示, 一般检测方法只越是红色虚线框与棕色框尽可能接近,而对于和蓝色框的关系不加约束。本文解决的正是这个问题。
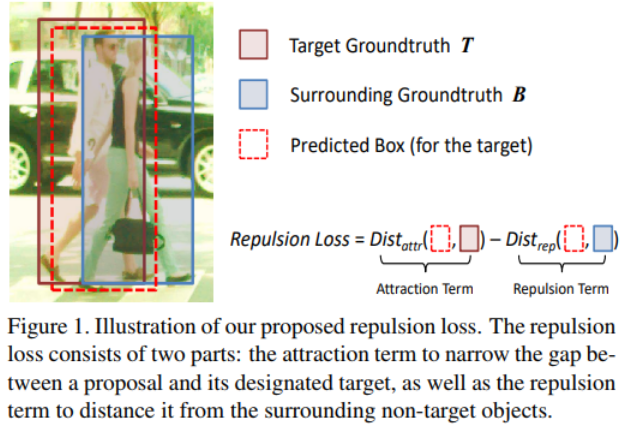
本文的贡献点:
- 实验分析了crowd occlusion对于行人检测的影响。在CityPersons benchmark上定量的分析了因crowd occlusion导致的false positives和miss detections的变化。
- 提出了两种repulsion loss处理crowd occlusion 问题: RepGT Loss和RepBox Loss。 RepGT loss惩罚的是预测框偏向其他的ground truth的程度, RepBox是为了让预测的box之间尽可能地分开,以削弱对NMS阈值的依赖。
- 利用提出的repulsion losses,训练了一个crowd-robust的端到端网络,并在CityPerson和Caltech-USA上验证了模型性能。另外PASCAL VOC数据集表明提出的repulsion loss对于通用目标的检测同样有积极作用。
拥挤遮挡分析
数据集合度量 CityPersons是语义分割数据集CityScapes上新创建的行人检测数据集。35000个人以及附加的13000左右的ignored regions, 提供了行人的bounding box和可见部分的标注。本文的实验都是在CityPerson的reasonable 的train/validation子集上进行的。评估使用FPPI(False Positives Per Image)的对数值.($MR^{-2}$) 该指标越小越好。
Detector 检测器使用的还是Faster RCNN框架。不同点在于将backbone由VGG-16替换成ResNet-50.注意 ResNet-50很少在行人检测中使用,主要是因为ResNet-50下采样的倍数太大,最终得到的特征太少。所以文章中使用了膨胀卷积(dilated convolution)使最后输出的特征大小事输入图像的1/8.ResNet-based 检测器在验证集上取得了$14.6 MR^{-2}$
检测失败原因分析
Miss detections.
数据集中样本的可见部分也使用box标注,所以样本的遮挡率可以得到 $occ = 1 - \frac{area(BBox_{visible})}{area(BBox)}$
在ground-truth上定义不同的子集。
occlusion case: $occ \ge 0.1$;
crowd occlusion case: $occ \ge 0.1$ 且存在至少一个gt box与其$IoU\ge 0.1$ .
按照上述定义, reasonable 验证集中1579个标注行人中,有$810(51.3)$的遮挡样本,称为reasonable-occ子集, $479(30.3%)$个crowd occlusion样本,称为reasonable-crowd子集。
下图分析了在reasonable, reasonable-occ, reasonable-crowd三种子集上miss detection的统计情况。
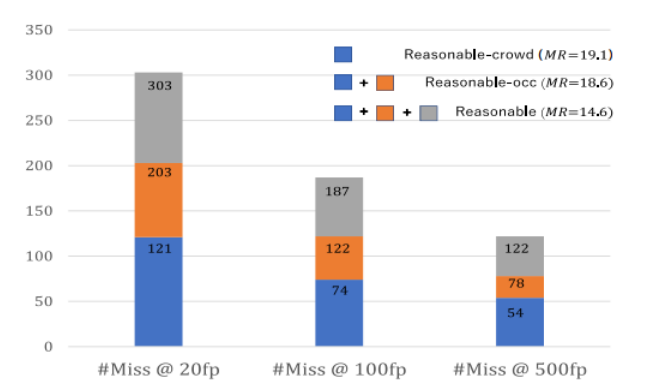
横轴的label表示在指定false positive数目条条件下,miss detection的数目, 比如#Miss@20fp表示调节参数使得保留20个false positive下的miss detection数目。可以看到在所有的miss detections中,源于reasonable-crowd的大约占了60%,表明crowd occlusion是影响detector性能的主要因素。另外通过降低NMS的阈值,如false positive从100到500, 因crowd occlusion引起的miss detections比例从60.7%上升到了69.2%, 表明NMS降低阈值并不能解决因crowd occlusion引起的漏检问题。
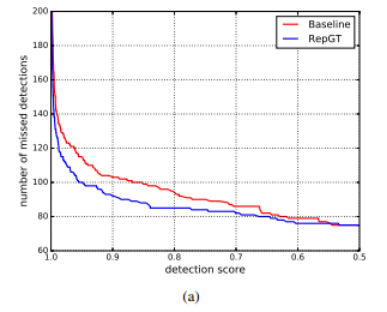
在下图(a)中,给出了miss detection 随着检测器置信度阈值增大的变化曲线。可以发现baseline方法在置信度较高时会产生更多的漏检,这部分主要是由于detections之间的重叠导致的。同时该图表明了RepGT对于miss detection和False positive的作用
False Positives
false positives可以分为三类:
- background error: 预测框和任意的target $IoU \le 0.1$;
- localization error: 与一个且只有一个target的$IoU \ge 0.1$ ,注意这里是指没有匹配上,但依然与某些目标存在IOU;
- Crowd error: predictions 与至少两个ground-truth的$IoU\ge 0.1$
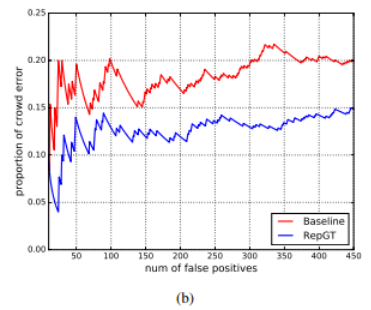
上图中的(b)图表示crowed errors随着false positives的变化所占的比例。可以发现其几乎稳定在$20\%$左右。
也表明在相同的False positive 数中RepGT loss中Crowd error的占比一直低于baseline中产生的Crowd error占比。
下图一些crowd error的例子。


其中绿色表示正确的匹配,红色表示crowd error。错误一般是由于向临近的目标偏移导致的。
Conclusion
The analysis on failure cases validates our observation: pedestrian detectors are surprisingly tainted by crowd occlusion, as it constitutes the majority of missed detections and results in more false positives by increasing the difficulty in localization.
Repulsion Loss
总的损失 $L = L_{Attr} + \alpha L_{RepGT} + \beta L_{RepBox}$
其中attraction term $L_{Attr}$表示预测框和真实框之间的相似度, $L_{RepGT}$表示的预测框与其它真实框尽可能地远离, $L_{RepBox}$表示预测框与其他target的预测框尽可能地远离。
$P = (l_p, t_p, w_p, h_p), G=(l_G, t_G, w_G, h_G)$ 分别表示提取的框和真实的框, $P_+=\{P\}$ 表示所有正样本组成的集合 (存在至少一个ground-truth背景 $IoU \ge 0.5$ ), $\mathcal{G} = \{G\}$表示所有的ground-truth
Attraction Term
其中 $G_{Attr}^P = arg max_{G\in \mathcal{G}} IoU(G, P)$
Repulsion Term (RepGT)
表示的是与预测框的IoU第二大的ground truth
其中$IoG(B, G) = \frac{area(B\and G)}{area(G)}$
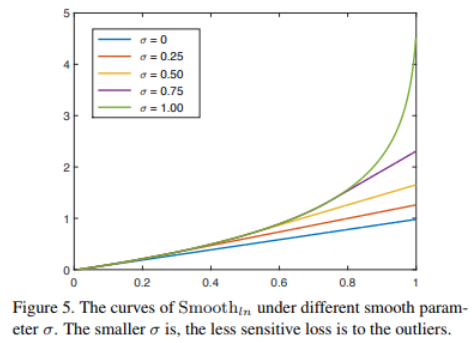
$\sigma \in [0, 1)$是光滑参数。
RepulsionTerm(RepBox)
为了让检测结果对NMS尽可能地鲁棒, RepBox Loss的目的是让predict与其他目标的target的尽可能地远离。将$P_+$ 根据IoU分配到$|\mathcal{G}|$ 中,$P_+ = P_1 \and P_2 \and \cdots \and P_{|\mathcal{G}|}$. 那么对于任意两个来自于不同子集的proposals,希望他们的重叠度尽可能的小
其中$\bold{1}$ 表示identity 函数, $\epsilon$ 是很小的常量防止除零操作。
Discussion
Distance metric。 在计算repulsion term时, 使用IoG, IoU而不是$Smooth_{L1}$ 是由于 IoG, IoU 取值[0,1],而SmoothL1无界, 使用SmoothL1会要求predicted box与repulsion ground-truth越远越好, 而IoG只是要求overlap越小越好,所以后者与我们设计思想更搭。另外在RepGT中使用IoG而不是IoU是因为,IoU-based loss可能导致enlarge bounding box增大union area来降低IoU,而IoG的降低则必须是overlap的降低.
Smooth Parameter $\sigma$ . 如下图. 所示$\sigma$ 可以调节repulsion loss对outliers的鲁棒性。
Experiments
Dataset
- CityPersons
- Caltech-USA 2.5小时的视频,划分为训练集(42500帧)和测试集(4024帧)
Training Details
- CityPersons: 80k iterations, init_lr = 0.016, 60k之后lr下降10倍
- Caltech-USA:160k iterations, init_lr = 0.016, 120k 之后lr下降10倍
- SGD
- 4 GPU
- minibatch=4
- weight decay=0.0001, momentum=0.9
- No multi-scale training/testing set used
- For caltech-USA, 10x set(~42k frames) is used for training
- Online Hard Example Mining (OHEM) is used to accelerate covergence
Ablation Study
RepGT Loss
Table 1中比较了不同的$\sigma$ 对SmoothL1loss的影响, $\sigma=0$ 意味着直接将 $-ln(1-IoG)$相加。
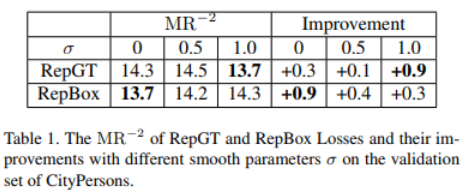
RepBox Loss
由table1可以发现在$\sigma=0$的时候RepBox Loss的性能最好, $\sigma=0$时相当于对IoU进行求和。这个可能是因为 RepGT处理的是预测和ground truth之间的重叠,这种情形下outliers其实很少,所以对outliers的抑制较大, 而RepBox处理的框更多,显然outliers也更多,这时候因为都是predict所以不知道之间哪个更可靠,就惩罚的少一点。
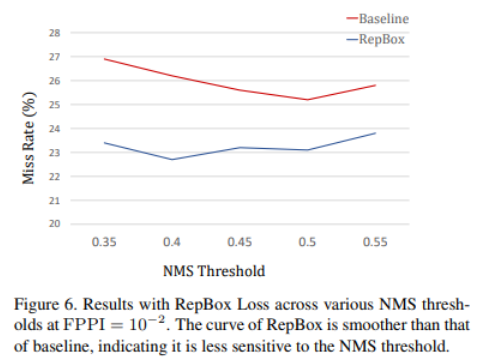
下图左给出了NMS在FPPI=0.01时不同阈值下,对应Miss Rate的变化,发现RepBox Loss 相对于baseline 对NMS的阈值更加鲁棒。下图右给的例子中显示的是在Crowd中也很少有predict处于两个ground-truth box之间,这样对NMS的阈值依赖更低.

Balance of RepGT and RepBox
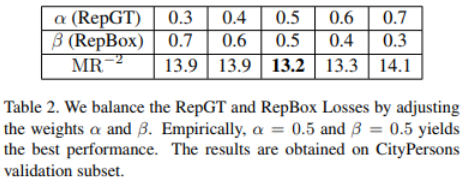
Table 2给出了不同的$\alpha, \beta$下RepGT和RepBox Loss的作用,实验表明$\alpha=0.5, \beta=0.5$时性能做好
Comparisons with state-of-the-art methods
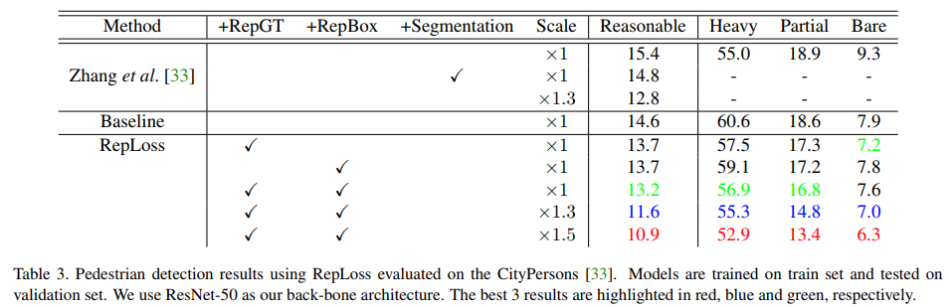
其中Reasonable set: $occlusion\le 35\%$; Partial set: $10\% \lt occlusion \le 35\%$; Bare set: $occlusion \le 10\%$ Heavy set: $occlusion\gt 35\%$ 。图8给出了具体的MR和FPPI的曲线图, 右上角的label对应IoU=0.5下的MR
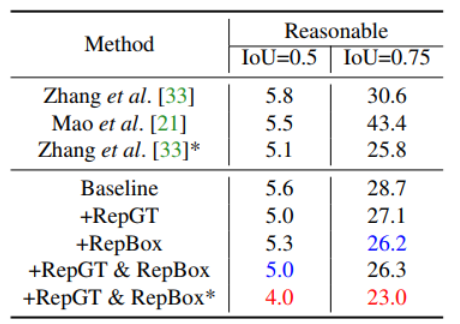
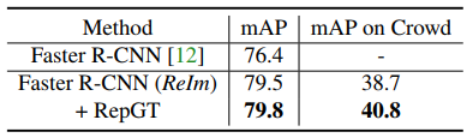
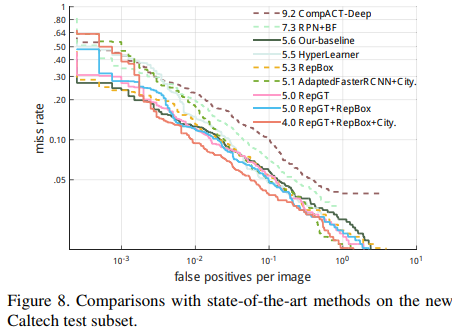
Conclusion
本文提出的loss其本质上创新性并不是很强,但作者针对于特定的问题提出了解决办法,并实验证明了算法有效。这点还是值得借鉴的。
本文作者 : zhouzongwei
原文链接 : http://yoursite.com/2019/05/21/repulsion-loss/
版权声明 : 本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明出处!
知识 & 情怀 | 赏或者不赏,我都在这,不声不响

