阅读笔记-FANTrack:3DMulti-Object Tracking with Feature Association Network
Abstract
目前大多数深度学习的方法主要基于特征的学习, 代价函数的设计,或者如何有效解决复杂的数据关联模型,很少有利用CNN网络端到端解决MOT的。本文提出使用CNN解决data association问题。该方案纯粹利用数据,从3D的角度实现全局的数据关联,同时处理noisy detections以及目标个数变化等问题。
文章提供代码: https://git.uwaterloo.ca/wise-lab/fantrack
Introduction
tracking-by-detection: 分为两个步骤。首先使用一个检测器从帧图像中将前景目标检测出来或者定位出来;然后在时间域内利用离散组合优化问题将noisy detections关联起来形成轨迹。
current challenges: 先验未知,但数目变化的目标个数; incorrect或者missing的detections; 因为传感器,光照,视角等变化导致的表观变化; 频繁的遮挡或者运动中出现的激烈变化等。
Milan 是第一个提出端到端实现MOT任务的, 其利用RNN解决数据关联问题。
A. Milan, S. H. Rezatofighi, A. R. Dick, K. Schindler, and I. D. Reid, “Online multi-target tracking using recurrent neural networks,” CoRR, vol. abs/1604.03635, 2016.
但是RNN的训练过程比一般的CNN训练难度大的多。
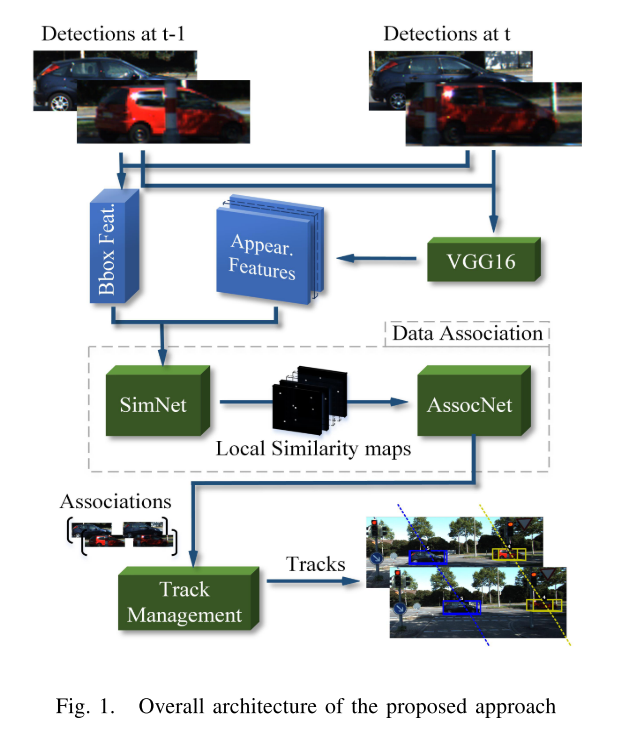
本文提出了一种基于CNN的两步骤关联推断算法。如下图所示。首先利用目标的表观和3D特征学习相似度函数。然后从提出的特征配对中利用CNN网络预测一个离散的关联矩阵。
在KITTI数据库上证明了算法的有效性:
- 能够利用CNN网络解决多目标关联问题。
- 同时利用了表观和3Dbounding box线索,或得到代价函数更加鲁棒。
- 性能与当前SOTA方法相当。
Approach
假设任意帧中都有$N$个目标,$M$条已有轨迹和对应的label, 检测器使用的AVOD 3D检测器。
Similarity Network
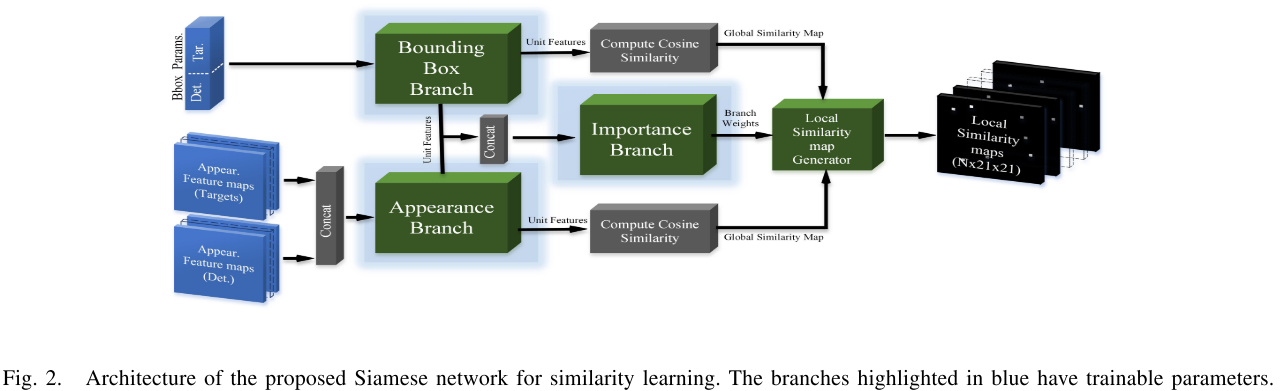
文章提出的Similarity Network如Fig2所示的SimNet。该网络有两个输入,分别对应这轨迹和检测的表观特征对,以及3Dbounding box的参数对, 3Dbounding box使用7维向量表示, 图像特征使用$7\times 7\times 320$维向量, 输出是$N_{max}$层feature maps。每个feature map大小是$10\times 10$, 每一个像素对应真实环境中$0.5m$的分辨率。feature map输出的是每一个目标与其他所有目标的相似度, 该feature maps被用于数据关联。
SimNet有两个分支: bounding box分支和appearance 分支, 每一个分支都是siamese结构判断两个输入相似与否。这两个相似度最终按照importance 分支的重要性程度进行加权。最后有这些特征获得similarity map
bounding box 分支
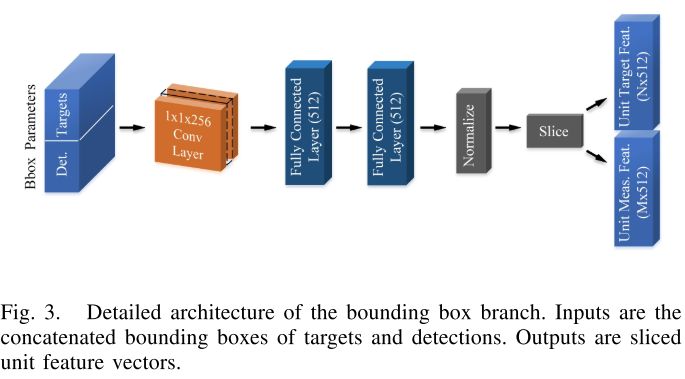
3D bounding box 的特征$(x, y, z, l, w, h, \theta_z)$分别表示中心点位置, 坐标对齐的长度以及z轴旋转角度。
输入是$(N+M)\times 1\times 7$放入$1\times 1$的卷积核两层全连接层后得到embedding特征,然后进行归一化处理,最后得到的特征用于计算余弦相似度。
Appearance分支
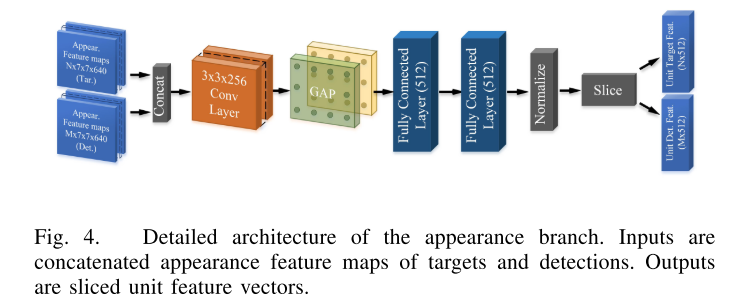
输入的是轨迹和检测concate的AVOD抽取的特征$(N+M)\times 7\times 7\times 320$, 这个特征是AVOD的第二和第四层的融合。在转成FC层之前引入了全局池化层以降低模型参数,最终归一化之后的特征用于计算余弦相似度。
Importance 分支
该分支主要用于计算bounding box分支和appearance分支的重要性程度
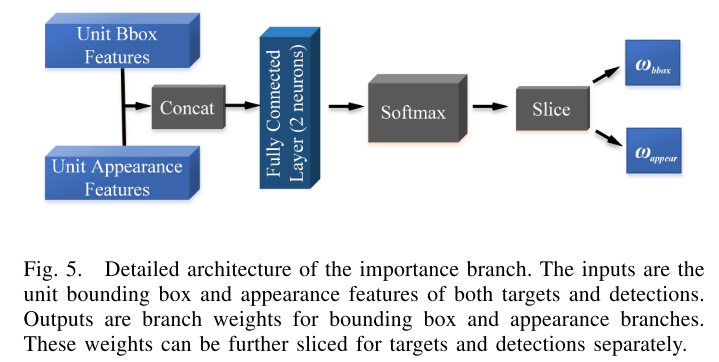
将特征concat之后进行一个2维输出,分别表示两者权重$w_{bbox}, w_{appear}$, 这部分权重没有标签,相当于学习出attention。
Similarity map
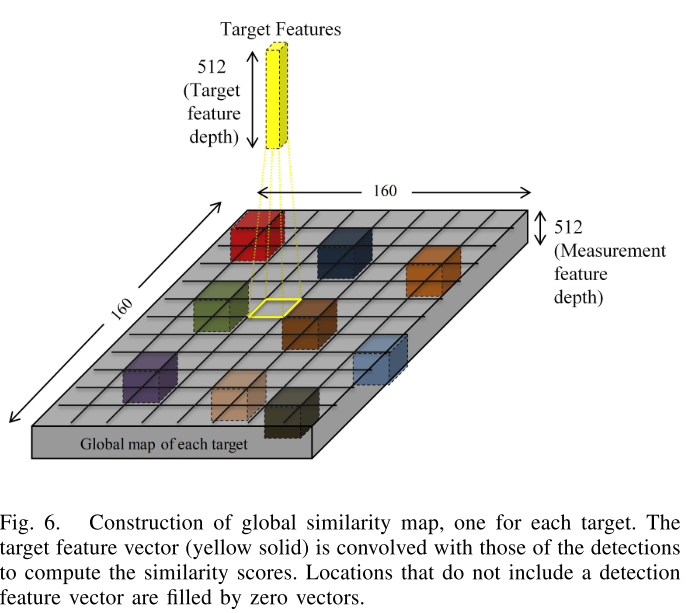
这张图表示的是一条轨迹与所有排列好的检测之间的相似度计算。将原始图像按照$0.5m$的距离划分成网格,然后将detections映射到对应的网格中,使用target的特征作为卷积核在网格上进行卷积得到global similarity map, 然后再从这张similarity map的target位置周围crop出$5\times 5 m^2$的区间,也就是$21\times 21$大小的map区域,于是$N$条轨迹最终获得$N\times 21\times 21$的similarity maps, 从similarity maps中直接学习匹配关系。
Loss Function
$\Theta_1$是待学习的参数, $N^+$表示非零权重的个数,$y^i\in \{-1, 1\}$是余弦相似度的label, $w_{skew}^i$有点类似于focal loss中$\gamma$的作用,用来平衡正负样本的影响, $w_{cost}^i$用来强调hard negative样本。 $\hat{y}^i(\Theta_1)$表示网络输出的最终余弦相似度
SimNet 创建训练样本
如果bounding box与某一个groundtruth 的IoU超过0.8则认为是正样本,另外为了增加样本多样性,如果proposals与当前已经确定类别的proposals的IoU大于0.95则抑制该proposals。
这里说的都是判断proposals与groundtruth的配对,也就是给proposals分配不同的ID,然后根据ID组成不同的正负样本对。
Data Association Network
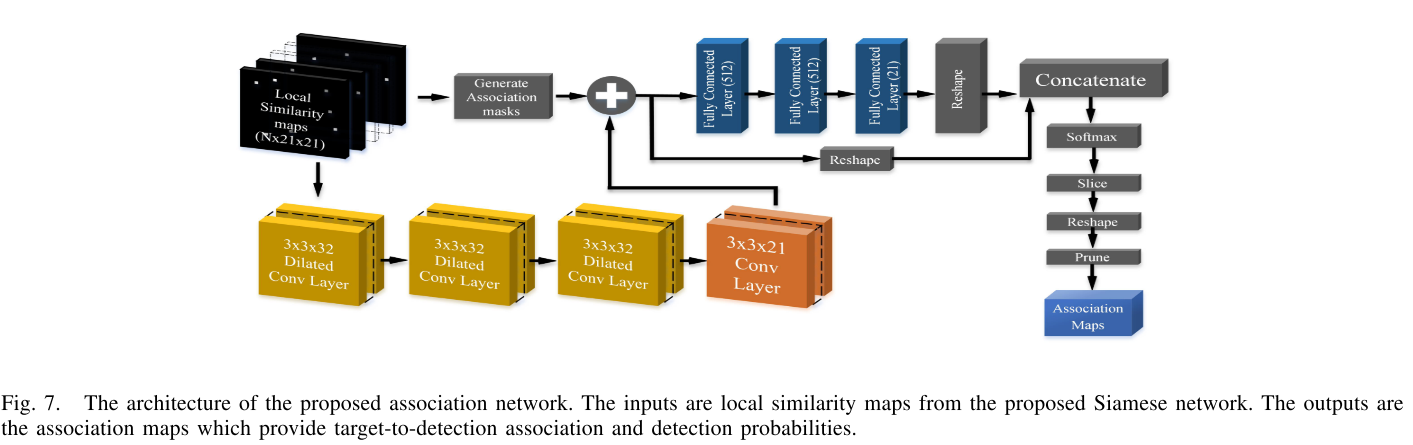
- 为了处理目标变化的情形, 设定了最大目标数$N_{max}$, 那么$N_{max}-N$称为dummy maps,有全0元素构成。
- 处理丢失的detection时,对每一个目标引入了一个额外的cell用于解释虚假检测。
输入数据,即$N_{max}\times21\times 21$的similarity maps首先输入到3层空洞卷积中,空洞因子分别为$2, 4, 6$, 然后后面接一层$3\times 3$卷积层用于计算logits maps。
由于目标和轨迹的相似度位置是已经确定的,所以网络计算association时只计算非零区域,于是设计了对每一层局部相似度map的association masks。 在masks中可能是检测的位置上为0, 否则则置为最小负值。 然后mask与logits maps叠加,这时可能是检测的区域特征被保存下来,不可能是检测的区域特征几乎都是最小值。
接着叠加的特征分成了两个分支,一个分支是全连接层用于判断该轨迹是否对应漏检。另一个分支将logits maps拉成1D向量然后与第一个分支的值concat一起,形成$N_{max}\times (21\times21+1)$的tensor,然后使用softmax计算$21\times 21+1$为的概率向量。 最终经过reshape获得关联概率矩阵,然后获得关联关系。这里的softmax相当于在2D上进行softmax,所以也就只关联到1个detection,但并没有办法保证1个detection仅关联了1条轨迹 。
- loss function前后两项分别表示二值交叉熵损失和正则化损失。这个式子是交叉熵损失函数。 $q_{assoc}^t(i,j) = 1-p_{assoc}^t(i,j)$
Track Management
利用kalman滤波预测运动目标的状态
利用概率值$P_e$创建贝叶斯估计模型初始化、更新和剪枝轨迹。

Experiments
Dataset
KITTI. 包含21段训练序列和29段测试序列。由于训练序列又按照难度、遮挡和模糊程度等划分不同的等级,作者选择每个层级的$20\%$用来验证。
Benchmark Results
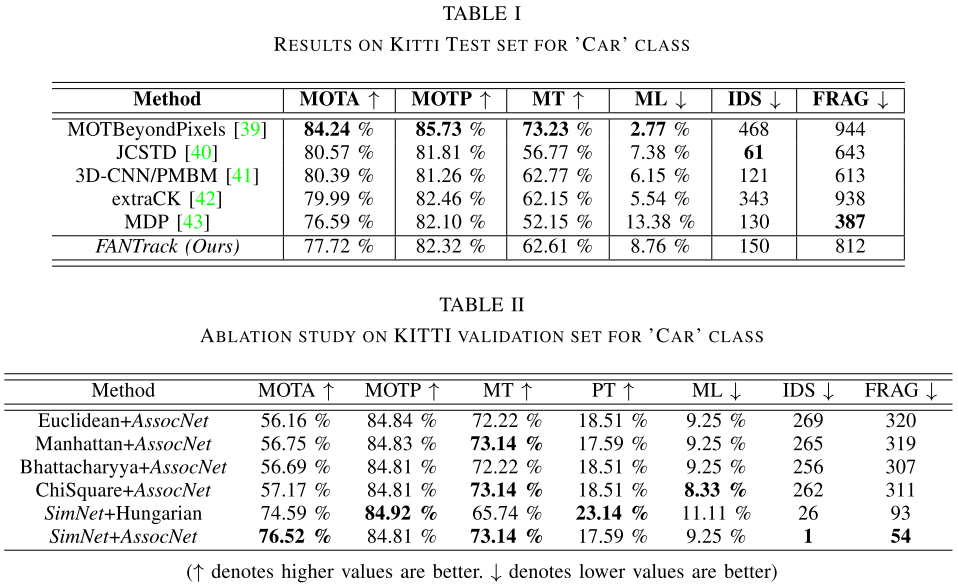
benchmark上的对比实验来看性能并不好。作者认为本文方法inference是在3D上进行的,而evaluation仅评估了2D指标,所以对于本文方法是不全面的,另外对比的方法都不是基于深度学习的数据关联方法。还有本文只是利用了kalman滤波进行运动状态的估计和预测, 如果用其他更复杂的算法性能或许更好。
Ablation分析对比了不同的特征抽取模块和关联模块,这个实验做的并不是很充分, 比如没有分析其他的特征抽取方法和匈牙利算法的性能如何,这样才能更好地体现SimNet的性能
Conclusion
- 本文方法输入需要是每一个检测的表观特征和3Dbounding box信息,这里说是计算轨迹和检测之间的关联,其实轨迹部分的特征如何选择并没有细说。
- SimNet抽取过程中2个分支分别计算表观和box的相似度,然后用importance branch计算每类相似度的权重,而这个权重的输入其实是concat的表观和box特征,感觉可能存在一些问题。
- SimNet抽取出来的是每个target与所有检测的similarity, 经过AssocNet获得association 概率,其实这个模块我觉得重要的有两点,其一是处理漏检,其二是全局的spatial softmax。
- 我认为方法还存在的不足在于并没有约束一个检测只能对应一个target。
本文作者 : zhouzongwei
原文链接 : http://yoursite.com/2019/05/22/FANTrack/
版权声明 : 本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明出处!
知识 & 情怀 | 赏或者不赏,我都在这,不声不响

