阅读笔记-Deep Affinity Network for Multiple Object Tracking
Abstract
MOT方法一般包含两个步骤:目标检测和数据关联。 目标检测这两年随着深度学习的发展而迅速发展,但是数据关联绝大多数还是采用hand crafted的方式将表观特征,运动信息,空间关系,group关系等进行结合。 这篇文章则是利用深度网络实现端到端的表观特征抽取和数据关联。 Deep Affinity Network(DAN)还实现了轨迹的初始化和终止等操作。在MOT15和MOT17,以及UA-DETRAC数据集上验证了有效性。这篇文章和上篇笔记FANTrack的出发点类似。
项目地址: https://github.com/shijieS/SST.git
Method
符号定义:
- $I_t$ 视频的第$t$帧
- $t-n:t$ 从$t-n$ 到$t$的时间间隔
- 下标 $t-n, t$ 表示元素是对$I_{t-n}, I_t$计算得到
- $\mathcal{C}_t$ 第$t$帧中目标的中心坐标的集合, $\mathcal{C}_t^i$表示集合的第$i$个元素
- $F_t$第$t$中目标的特征集合, $F_t^i$表示$t$帧中第$i$个目标的特征
- $\Psi_{t-n,t}$是一个$N\times N\times 2M$的tensor,其中N表示目标的个数, $M$表示每个目标特征向量的维度,$N\times N$表示的任意两个来自于不同帧的目标配对,相当于global association。
- $L_{t-n, t}$二值关联矩阵, 1表示关联, 0表示不关联, 表示来自于两张图片中目标的关联矩阵。这里包含了终止和起始状态。
- $A_{t-n, t}$相似度矩阵, 由$\Psi$到$A$进而得到$L$
- $\Tau_t$ 直至第$t$帧时的轨迹的集合。轨迹使用二元组的集合表示,$\Tau_t^i=\{(0,1),(1,2)\}$表示轨迹中的关联是第0帧的第一个目标和第1帧的第2个目标。
- $\mathcal{Z}(\cdot)$算子用来计算集合或者矩阵中的元素
- $\Lambda_t\in R^{\mathcal{Z}(\Tau_{t-1})\times(\mathcal{Z}(\mathcal{C_t})+1)}$ 是一个accumulator matrix,其元素表示目标与轨迹的相似度
- $N_m$表示每一帧中最大允许的目标个数, $B$是batchsize
Deep Affinity Network (DAN)
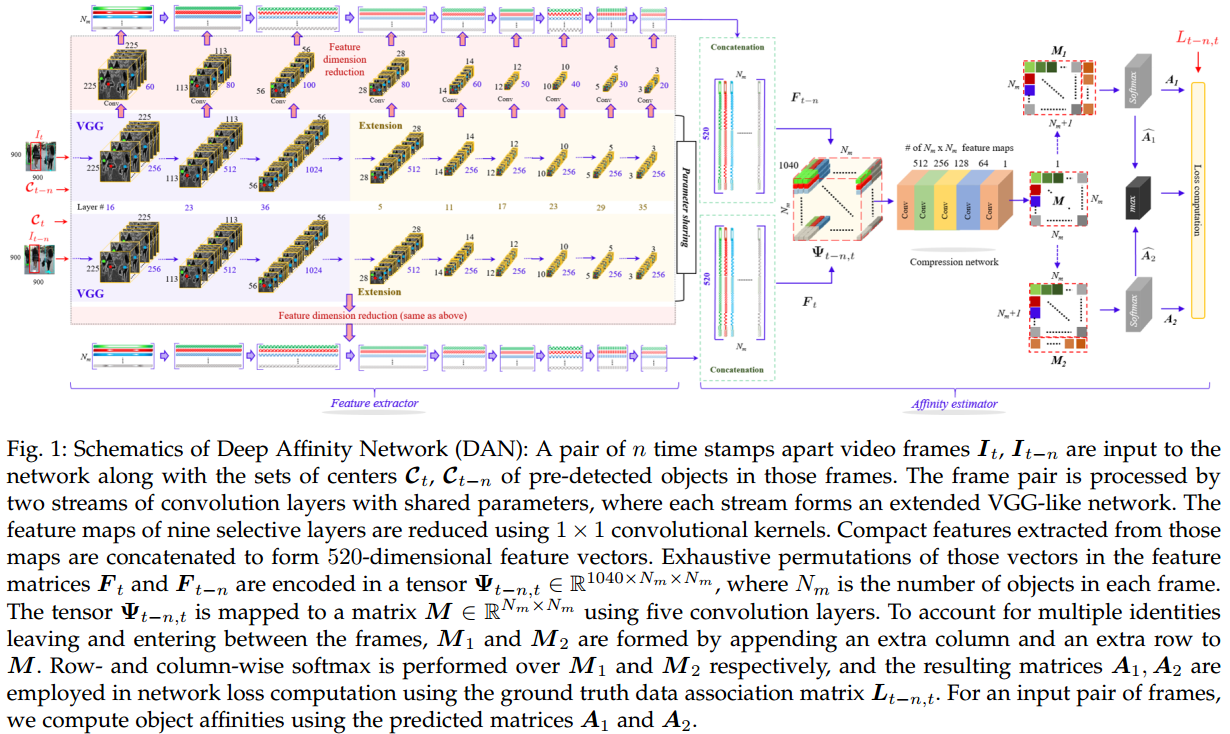
如图1所示, DAN包含了两部分:特征抽取模块(feature extractor)和相似度估计模块(Affinity estimator), 整体的训练是end-to-end方式的。
DAN的输入是两幅图像$I_t, I_{t-n}$以及每幅图像中对应目标的中心点坐标$\mathcal{C}_t, \mathcal{C}_{t-n}$, 这里不要求两幅图像连续, 时间间隔$N\in\mathbb{N}^{rand}\sim [1, N_V]$.
DAN的输出应该是两幅图像中目标的关联矩阵$L_{t-n, t}$
其主要过程:
输入时序上的两帧图像$I_{t-n}, I_t$(非必须连续)及其对应检测的中心点集$C_{t-n}, C_t$, 将两幅图像送入VGG-like的共享参数Siamese网络,从网络中选择了9层feature maps, 然后从其中利用中心点集和$1\times 1$的卷积核对每个目标构建了$520$特征向量集合$F_t, F_{t-n}$。
来自于$F_{t-n}, F_t$的特征进行完全的两两匹配,形成张量$\Psi_{t-n,t}\in R^{1024\times N_m\times N_m}$, 该3D张量经过5层卷积将通道数降维1, $M\in R^{N_m \times N_m}$, 该矩阵其实表示的任意两个目标之间关联的可能性。
同时为了刻画轨迹的起点和终点,在矩阵$M$上分别添加augmented行和列, 然后通过按行或者列softmax或者关联矩阵$A, A_1, A_2$计算损失函数进行训练。
Data Preparation
- Photometric distortions: 像素值尺度变化$[0.7, 1.5]$, 转换成HSV空间, 饱和度的尺度变化$[0.7, 1.5]$, 然后再转回到RGB中,同样尺度[0.7, 1.5]的变化
- 使用图像像素均值expand frame, 尺度变化范围$[1, 1.2]$
- 图像裁剪, 尺度范围$[0.8, 1]$, 同时需要包含所有检测目标的中心点
以0.3的概率按上述方法扩展样本对。然后图像固定大小$H\times W\times 3$, 图像水平翻转的概率$0.5$
MOT中每一帧存活的轨迹个数不是固定的,给网络的训练带来难度。因此文章给出了一个轨迹个数的上限值$N_m=80$ , Fig.2 给出了关联矩阵的构建示意图。这里为了清晰演示,取$N_m=5$. 第1帧和第30帧图像各检测到4个目标, 总共有$5$个人。 Fig.2c展示了包含dummy row和column的中间矩阵$L_{1, 30}’$的构建, dummy row或者column用来表示dummy bounding box,从而让关联矩阵大小一致,不随目标个数变化而变化。 Fig.2d中关联矩阵进一步augmented引入新的row和column,表示新出现的目标和终止的轨迹。最终使用Fig.2d的矩阵作为训练目标。最后一行或者列中包含多个1则表示多个目标终止或出现。
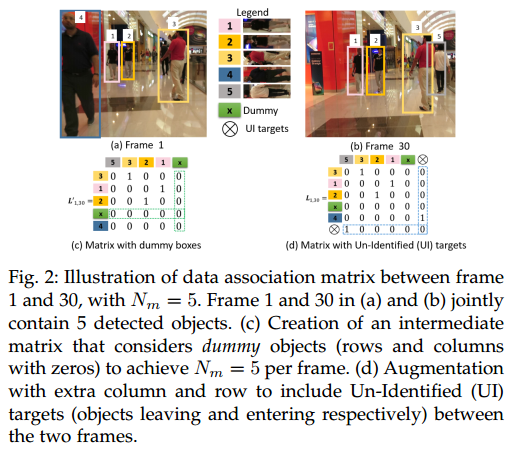
这里dummy行或者列与augmented行列是不同的, dummy是用来保证总体的匹配个数相同,需要服从每一行或者列最多只能有1个非零元素,augmented则是用来刻画轨迹的终止和起始,对其非零元素的个数没有约束。允许多条轨迹同时结束, 多个目标同时作为多条新轨迹的起点。
Feature extractor
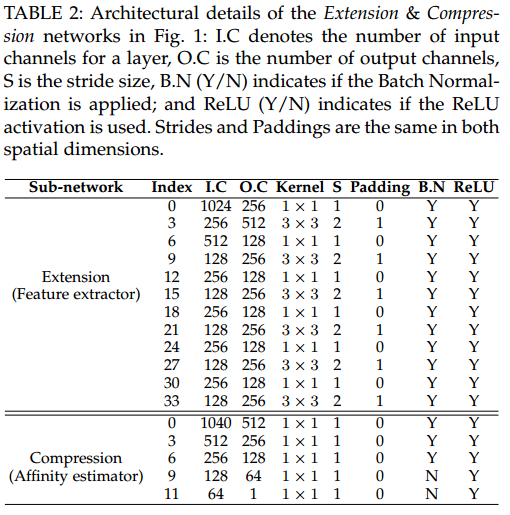
在VGG16上进行了修改, 将VGG16后面的全连接层和softmax层都换成了卷积层,这么做主要是卷积层能够更好地encoding目标的空间特征并且可以从空间上抽取每个目标的特征。另外这里的输入数据也更大$3\times 900 \times 900$, 从而修改后的VGG16最后一层的输出还有$56\times 56$大小。 VGG16最后输出的$56\times 56$的feature map采用表2上半部分的结构进一步缩小到$3\times 3$
特征抽取和估计affinity的网络参数如下表:
修改后的feature extractor网络具有33层卷积层,然后从中选择了9层作为最终提取特征的层,其选择的层数索引,以及如何从该层降维获得表观特征参数如下
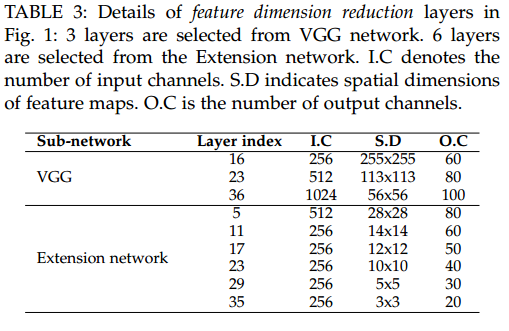
利用目标的中心坐标$\mathcal{C}_t$在channel上选择特征,降维采用的$1\times 1$的卷积核, 特征进行concatenate。最终每一个目标形成$520$维的特征向量。对于那些dummy的目标,其特征表示为全零向量。
Affinity estimator
feature extractor之后每幅图像抽取的特征$F_t\in R^{N_m\times 520}$,然后将两幅图像目标的特征任意的组合就形成了tensor $\Psi\in R^{(520\times 2)\times N_m\times N_m}$, 然后在利用5层卷积核为$1\times 1$的卷积层压缩维度形成相似度矩阵$M\in R^{N_m\times N_m}$,压缩网络的模型如Table 2的下半部分所示。
这里的M对应于真实的Label,即两个目标是否关联。但是没有解释新出现的轨迹和离开的轨迹。因此文章对相似度矩阵$M$进行了扩充。为了让模型更好训练以及loss更好定义,这里$M$分开进行行列扩充,扩充的向量$\textbf{v}=\gamma \textbf{1}$ , $\gamma$是超参。
Network Loss
$M_1\in R^{N_m\times(N_m+1)}$列扩展矩阵每一行表示第$m$个目标关联情况或者是否结束。 $M_2\in R^{(N_m+1)\times N_m}$行扩展矩阵对应了反向匹配时第二幅图像中目标的关联情况或者是否是新出现的轨迹。对行,列扩展矩阵$M_1, M_2$分别进行行,列softmax得到$A_1, A_2$表示的是概率。
因此DAN网络损失包含4部分:前向损失,后向损失,一致性损失和组合损失
其中$L_1, L_2$都是与$M_1, M_2$对应的$L_{t-n, t}$的trimmed 版本, $\widehat{A_1}, \widehat{A_2}$是trimmed成$N_m\times N_m$的版本, $L_3$则是同时去掉了最后一行和最后一列。
四种Loss损失:
- 对于前向和后向损失,文章并没有直接使用输出$A_q(q=1,2)$与目标$L_q(q=1,2)$的距离作为损失, 而是采用$A_q$在真实关联位置的相对系数,也就是$-\log(A_q)$作为优化目标,这种方法其实是让关联位置的输出概率更快的接近于1, 而对于其他非真实关联的位置,由于$A_q$采用了行或者softmax,所以就非常接近于0.
- 截断后的关联矩阵,即不考虑augmented 行和列后的部分应该是相同的,所以文章使用$L_1$范数约束距离, $L_1$比$L_2$在较小范围内更加紧致。
- $L_a$和$L_q(q=1,2)$类似, 不同的是选择最大$\widehat{A_1}, \widehat{A_2}$作为最终的关联矩阵。
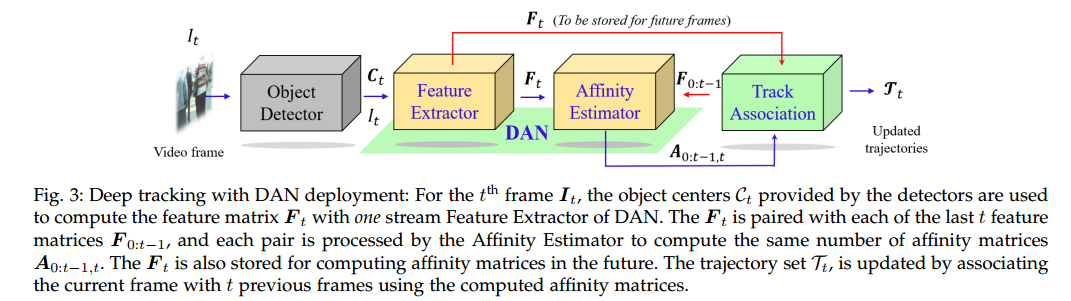
DAN deployment
因为feature extractor部分是参数共享的,而在计算相似度矩阵的时候只是后面的affinity estimator牵涉到两两相互操作,因此,每张图片其实只进行一次feature extractor的操作,后面的affinity estimator是进行匹配。
Deep track association
这部分很关键。为了匹配当前帧中的目标, 将每一帧的特征矩阵$F$和对应的时间戳保存起来,然后可以计算历史frames与当前frame之间的相似度矩阵。
关联过程: 首先根据第1帧图像中的目标个数初始化轨迹集合$\Tau_0$,轨迹中每一个元素是一个二元组(时间戳, 轨迹编号),使用hungrain algorithm对accumulator matrix $\Lambda$分解去grow对应的轨迹, $\Lambda$是当前帧目标与多个历史帧目标的相似度矩阵的累积求和,注意这里累积求和是相同轨迹编号进行求和。
注意这里有个问题,匈牙利算法是一对一约束,但相似度矩阵中添加的最后一行一列不满足这个要求,于是匈牙利算法对最后一列进行repeating,直至所有的trajectory都能得到匹配。
Experiments
实验部分还是很充分的,在MOT15和MOT17上进行了行人跟踪的实验, 在UA-DETRAC上进行了车辆的跟踪。

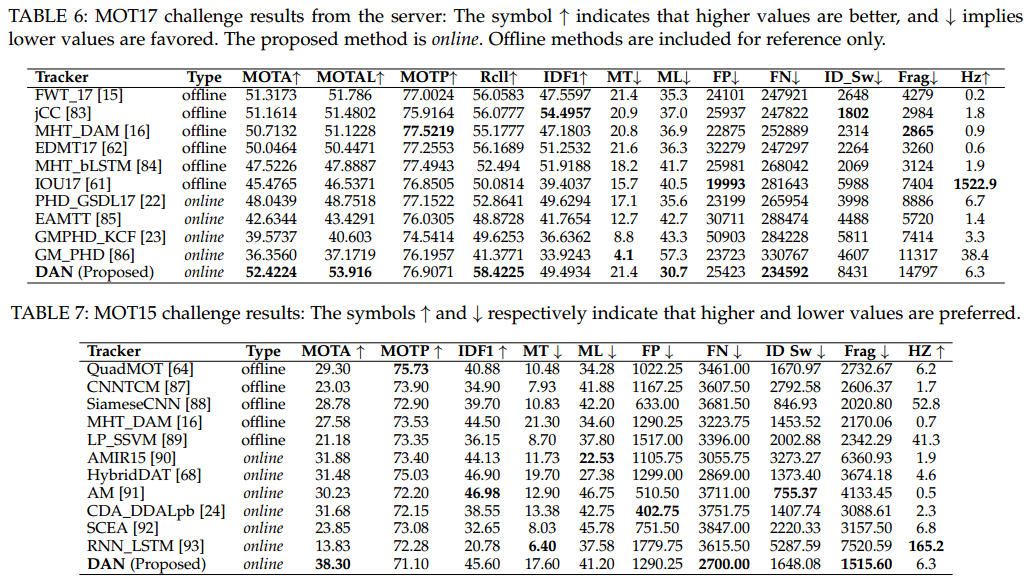
这里有个指标有问题$MT$应该是越大越好

Conclusion
实验没有给出在MOT16上DPM检测器下的跟踪性能,我跑了下代码发现性能很差。在MOT17库上性能好是因为MOT17库上的检测相对准确。也就是说该方法其实对于检测的精度还是非常依赖的。因为网络的输入是目标的中心点坐标,并且在抽取特征阶段是利用中心点位置channel 作为特征,检测误差必定导致特征的不准确,从而影响性能。
另外值得一提的是,这篇文章也只利用的表观信息,如何更好地利用空间信息也是个研究方向。
本文作者 : zhouzongwei
原文链接 : http://yoursite.com/2019/05/22/SST-DAN/
版权声明 : 本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明出处!
知识 & 情怀 | 赏或者不赏,我都在这,不声不响

