阅读笔记-Relation Network for Object Detection
Abstract
我们都知道在目标检测领域,深度学习(RCNN系列,YOLO系列,SSD系列)方法取得了很大的成功,但是这些检测方法考虑的仅仅是目标的个体,而没有考虑一帧图像中目标之间的相互影响,所以本文提出一种object relation module ,通过考虑目标集合中个体的交互关系来辅助目标的检测。该模块参数很少能够很方便的嵌入到已有的网络中,提高目标检测性能,另外本文使用该模块实现duplicate removal(NMS实现的功能),从而能够实现网络的end-to-end学习。
思考_ : 在多目标跟踪问题中,一般的计算两个目标之间是否匹配的策略还是类似于ReID的方法,仅考虑两者之间的相似度,但是在跟踪的时空图中,两个观测的关系不仅仅取决于两者之间的关系,还取决于同时存在的其他目标之间的关系,所以多目标的匹配策略同样可以使用类似的relation module。
Object Relation Module (ORM)
文章在处理object之间关系时主要借鉴和继承了google的关于attention的开山之作
Attention is all your need
具体而言,假设经过特征抽取网络,比如RPN层结果,获得了$N$个候选目标的表观特征$f_A$和几何特征$f_G$,也就是bounding box特征。 $N$个特征表示为$\{(f_A^n, f_G^n)\}_{n=1}^N$, 那么经过relation module之后的特征$f_R(n)$如下计算
可以看到$W_v$其实是对表观特征先进行一次embedding,然后使用一组与目标$n$有关的权重进行加权求和作为第$n$个样本新的特征,所以这是一种Attention的操作。
而权重的计算结合了空间几何特征和表观特征,其模块计算图如下:
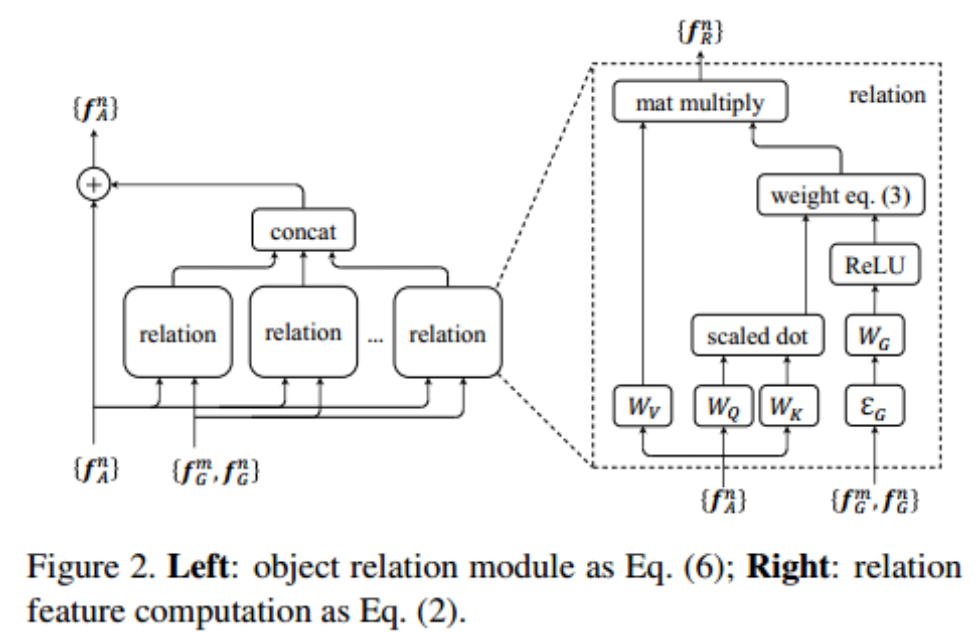
具体公式如下:
其中$W_A, W_V, W_Q, W_k$都是需要学习的参数,$\Epsilon(\cdot,\cdot)$是特征融合函数,可以使用网络实现,论文中类似于’Attention is all your need’的做法,使用cosine和sine functions融合位置参数$f_G=(\log(\frac{|x_m-x_n|}{w_m}),\log(\frac{|y_m-y_n|}{h_m}),\log(\frac{w_n}{w_m}),\log(\frac{h_n}{m_m}))$
由于空间中目标个数也是不定的,所以其实就是在图上进行一种attention, 可以参考论文Graph Attention Network(GAT), 同样的类似于GAT方法,文章中也使用了multi-head attention的一种方式,如Figure 2所示,每一个relation模块是一种attention, 多个attention 模块同时作用, 文中取16个这种模块。 另外attention之后的特征和原始特征进行相加,这类似于Graph Convolution Network中邻接矩阵的归一化加上单位阵的操作。
如果将所有attention的结果等长加在一起会导致计算量太大,所以这里将所有的attention结果concat在一起和原始的特征加在一起减小运算量,但文章没有实验对比性能有什么差异。注意每一个attention模块的输出大小应该特殊设置,以使得最后concat之后特征与原始特征等长从而能够进行相加操作。
Relation Networks for Object Detection
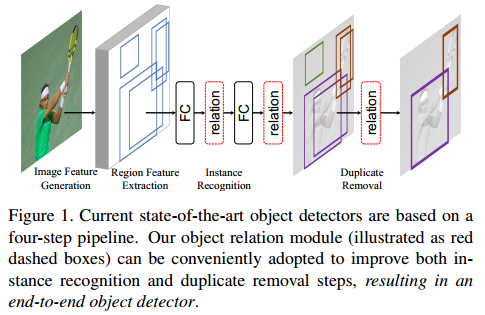
相对于已有的object detection框架而言,简单的增加了两个模块,如下图所示。(a)用于刻画Instance之间的关系,(b)用于去除重复的Instances,下面会介绍两个模块。
第一个模块是用于从每个目标所处的空间关系出发,融合目标的context信息从而提取更好地特征, 第二个模块是希望利用目标之间的位置关系将NMS的过程融合到网络里面从而避免阈值的选取。注意(b)图中$s_0, s_1$是乘法操作。
Relation for Instance Recognition
以RCNN为basenet,RCNN在ROI pooling之后过程如下:
加上relation module,即Figure 2模块在FC之后得到计算过程如下:
这里$r_1, r_2$分别表示每个RM模块中head的个数,可以选择不同的数值。
Relation for Duplicate Removal
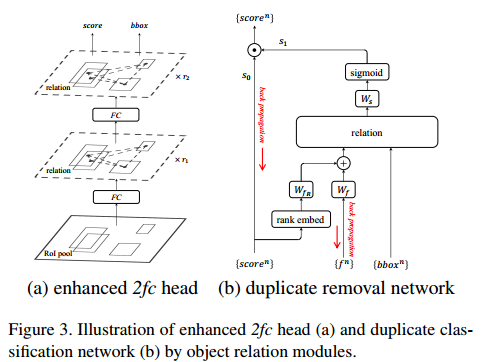
作者把duplicate removal归结成一个二分类问题,对于每一个gt box,只有一个detected box是正确的,其他的都是所谓duplicate。作者的duplicate removal network是接在classifier的输出后面。该模块的输入包括object proposal的 score vector(属于各个类别的概率), bbox,以及proposal的特征(典型的1024维)。对于某一个object proposal的某一个类别,假设属于这个类别的概率为$score^n$,首先经过一个rank embed模块,即拿出其他object proposal属于该类别的score,进行排序,得到第n个object proposal在排序中的下标(rank),作者特别说明了,使用rank值而不是直接score的值非常重要。然后将rank值映射到128维向量,同时将该proposal的特征也映射到128维,将两种128维的特征相加之后作为新的appearance feature,然后和bbox作为relation module的输入,得到新的128维的输出,和$W_s$做内积之后通过sigmoid得到$s_1$,最终的correct的概率$s=s_0 * s_1$
我觉得这部分选择rank而不是score作为特征的原因在于rank是一种序列特征,其与score的具体数值无关。
End-to-End Object Detection
这一部分我觉得挺有意思的。
end2end training就是把两部分损失叠加起来,但是直观上而言会存在一些问题。
首先, instance recognition step和duplicate removal step目标是相反的, instance recognition step是将所有可能是目标的区域都尽可能的获得较高的置信度,而duplicate removal step却要求部分可能是真值得候选区域只选一个其余的置信度要尽可能的低。这个问题实际上不冲突的关键就在于duplicate removal模块中$s_0, s_1$乘积作用, $s_0$可以保留instance recognition step的作用,$s_1$用来达到duplicate removal step的目标。
duplicate removal 模块并没有确切的标签,其标签是通过instance recognition 模块输出与真实标签的覆盖程度确定的,因此训练过程标签中是会发生变化的。这种变化会不会导致训练不稳定?文章指出实验中并没有出现不稳定的现象.
While there is no theoretical evidence yet, our guess is that the duplicate removal network is relatively easy to train and the instable label may serve as a means of regularization.
Experiments
文章中所有的实验都是在COCO数据集上完成
Relation for Instance Recognition
对比试验中NMS的阈值设为0.6,(a)中none表示不使用几何信息,$w_g=1$, unary表示使用的是[1]中的embedding方法,(b)中是attention head的个数,(c)中是每个阶段使用relation module的个数

结论:
- relation attention 能够提升检测性能
- 几何特征能够提升检测性能
- attention head的个数增多能够提升检测性能,文中实验在16时达到饱和
- relation module的模块个数能够提升检测性能
Does the improvement come from more parameters of depths?
我觉得这个对比实验做的很好,引入attention后相当于网络多加了一些参数和层,那么到底是attention机制有效还是参数更多了有效?
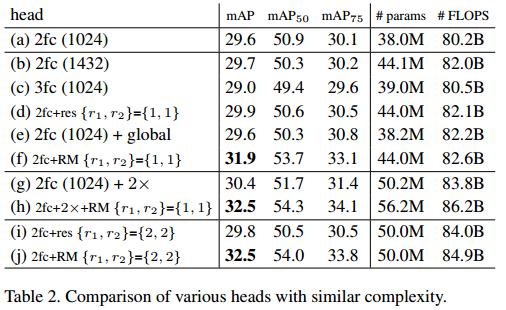
table 2 表明相同深度下使用和不使用relation module的性能已经不同的heads的性能对比。
- A wider 2fc head (1432-d, b) only introduces small improvement (+0.1 mAP).
- A deeper 3fc head (c) deteriorates the accuracy (-0.6 mAP), probably due to the difficulty of training.
- To make the training easier, residual blocks are used5 (d), but only moderate improvement is observed (+0.3 mAP).
- global context is used (e, 2048-d global average pooled features are concatenated with the second 1024-d instance feature before classification), no improvement is observed.
- our approach (f) significantly improves the accuracy (+2.3 mAP).
- nother baseline which concatenates the original pooled features with the ones from a 2× larger RoI (g), the performance is improved from 29.6 to 30.4 mAP, indicating a better way of utilizing context cues.
- we combine this new head with relation modules, that is, replacing the 2fc with {r1, r2}={1, 1} (h). We get 32.5 mAP, which is 0.6 better than setting (f) (31.9 mAP). This indicates that using a larger window context and relation modules are mostly complementary.
- When more residual blocks are used and the head network becomes deeper (i), accuracy no longer increases.
- accuracy is continually improved when more relation modules are used (j).
对比实验从各个角度证明了文章提出的RM的有效性。
Relation for duplicate removal
backbone-network : Faster RCNN
前面我们提到在for duplicate removal模块是,输入特征是bbox和rank与appearance embedding之后的特征和。那么不同的输入会有什么影响。
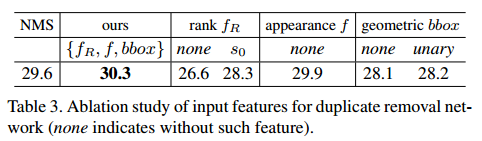
单独使用NMS, 阈值0.5的时候AP是29.6, 第二列正是算法最终使用的特征,即rank对应的特征,表观特征和bbox特征,第三列表示当不使用rank特征时,AP=26.6下降严重,说明rank特征有用。第三列的第二子列表示将rank特征用score特征取代,发现性能也会下降。第四列表示不使用表观特征,这时候可以发现只利用rank和box特征相对于NMS性能也是提升的。第五列的第一子列表示不使用bbox信息,第二子列表示计算bbox的attention 权重时方式不同,是将$f_G$映射到高维空间然后加到$f_A$上作为新的特征,发现这两种方式性能都下降了。
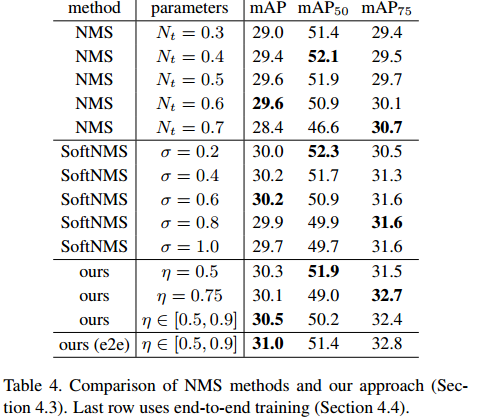
对比了不同阈值下NMS和本文relation module进行抑制duplicate的性能。NMS的阈值是IoU的阈值, 本文的阈值是二分类问题的阈值。最下面一行表示end-2-end训练,发现性能提升还是很明显的。

Conclusion
大多数的目标检测算法都仅考虑了目标本身(最后的分类层不纳入考虑,因为分类层是指定类别,与proposal位置无关), 本文则是考虑了目标之间的相互作用,目标之间的关系对于目标的检测还是有帮助的,比如行人检测时,两个行人交互时一定是存在特殊约束的,而这种约束则可以通过相互关系进行抽象。同时利用目标关系来实现NMS的功能是一个较大的创新点。
本文作者 : zhouzongwei
原文链接 : http://yoursite.com/2019/05/22/relationNetwork/
版权声明 : 本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明出处!
知识 & 情怀 | 赏或者不赏,我都在这,不声不响

