CenterNet的代码在train.py文件中自己定义了多线程的数据处理方式,而不是用的pytorch自带的,所以这里来分析一下这部分的实现。
头文件导入多线程处理包
1
2
| import queue
from torch.multiprocessing import Process, Queue
|
queue主要用来创建队列,阻塞型队列,当queue满的时候再执行put操作,则暂时阻塞直到有空位置腾出来再继续进行,同样当queue为空的时候执行get操作也会暂时阻塞。
multiprocessing中的Queue和queue.Queue功能差不多,但是他能实现多进程之间数据的共享。
Process多进程包。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
|
def train(training_dbs, validation_db, start_iter=0):
...
training_queue = Queue(system_configs.prefetch_size)
validation_queue = Queue(5)
pinned_training_queue = queue.Queue(system_configs.prefetch_size)
pinned_validation_queue = queue.Queue(5)
data_file = "sample.{}".format(training_dbs[0],data)
sample_data = importlib.import_module(data_file).sample_data
training_tasks = init_parallel_jobs(training_dbs, training_queue, sample_data, True)
if val_iter:
validation_tasks = init_parallel_jobs([validation_db], validation_queue, dample_data, False)
training_pin_semaphore = threading.Semaphore()
validation_pin_semaphore = threading.Semaphore()
training_pin_semaphore.acquire()
validation_pin_semaphore.acquire()
training_pin_args = (training_queue, pinned_training_queue, training_pin_semaphore)
training_pin_thread = threading.Thread(target=pin_memory, args=training_pin_args)
training_pin_thread.daemon = True
training_pin_thread.start()
...
with stdout_to_tqdm() as save_stdout:
for iteration in tqdm(range(start_iter+1, max_iteration+1), file=save_stdout, ncols=80):
training = pinned_training_queue.get(block=True)
...
training_pin_semaphore.release()
validation_pin_semaphore.release()
for training_task in training_tasks:
training_task.terminate()
for validation_task in validation_tasks:
validation_task.termination()
|
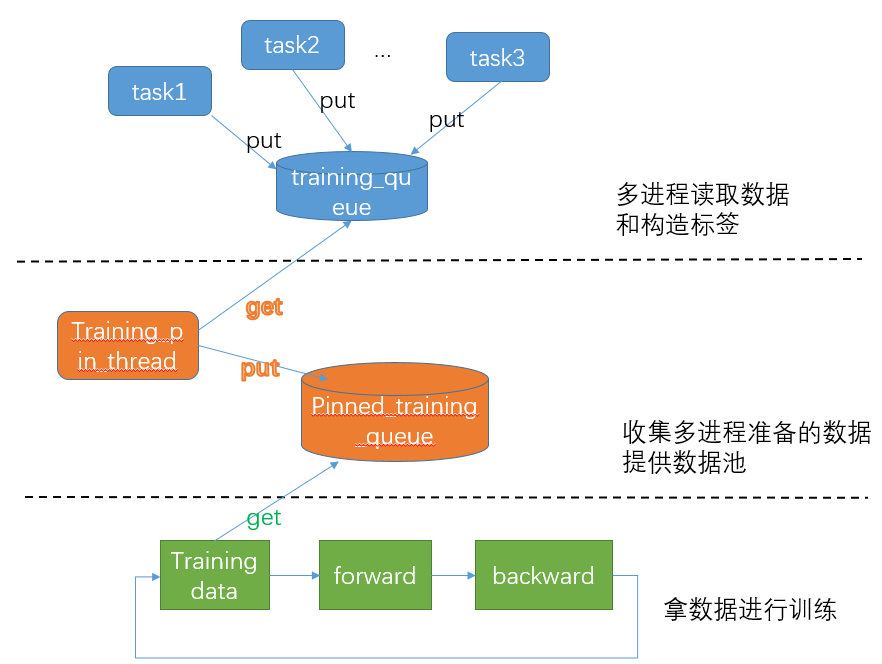
这部分代码并行处理大致可以分为3部分。以下面的图示来讲三个阶段大体上是并行的,通过两个队列来进行传递数据。另外与主线程的归属公国daemon和信号量实现: