阅读笔记-Online Multi-Object Tracking with Instance-Aware Tracker and Dynamic Model Refreshment
摘要
随着单目标跟踪方法(SOT)的快速发展,许多将单目标算法应用到多目标任务上的方法也相继被提出。model-free型单目标跟踪算法不需要依赖于检测器。但是SOT一般针对于首帧标定的目标区域,主要用来鉴别目标和周围环境,所以直接应用到多目标任务中效果并不好,因为MOT中往往多个同类的目标聚集一起。针对于这个问题, 本文提出一种通过编码对环境和其他目标集成SOT的instance-aware跟踪器用于多目标跟踪。具体而言就是通过融合对其他目标和周围环境的鉴别信息为每个目标构建跟踪模型。为了保持每个模型的独一性,instance-aware模型又结合了响应图和空间位置关系进一步提升精度。 文章另一个贡献点是利用深度网络动态的更新模型。这种做法可以帮助减少初始化噪声以及适应目标尺寸和表观变化。
Introduction
大多数基于检测的多目标跟踪方法虽然性能较好,但是, 检测和跟踪分离开会导致丢失了帧与帧之间的相关关系,将视频中目标检测简化为了静态图像的目标检测(注:目前基于视频的目标检测研究也在不断进步), 另外对检测器的依赖也使得跟踪算法在处理复杂场景时由于检测器性能的急剧下降而导致跟踪性能的大幅下降。
另一方面MOT可以看做是SOT的一种推广,即多个SOT同时运行。SOT在近些年研究取得了极大进展。但是,即使选取合适的trajectory management策略, 将SOT直接应用到MOT任务中也会遇到各种问题
SOT一般为了更好地处理表观变化,模型空间往往更大,但是在MOT场景中,SOT的搜索区域内可能存在多个表观非常相似的不同目标,这就会导致SOT频繁的匹配错误。还有一个更严重的问题, SOT一般模型都取决于第一帧中标定的区域,那么在MOT中必须在每一条轨迹第一次出现时就有非常精确的标定,但MOT中的候选框都是检测器得到的,不可避免的包含各种噪声。
这篇文章提出一种instance-aware的跟踪器,希望(harvest)同时吸取SOT的优势和解决SOT存在的问题。具体而言,对于每一个目标, IA(Instance-Aware) 跟踪器是一个高效的KCF框架, 能够通过特征融合区分目标与其他目标个背景区域。这里的aware就是指target和其他targets之间的鉴别性。而对于整体而言,所有目标模型生成的响应图被集成起来用于预测下一帧中目标的位置。模型的更新过程则是通过一个自适应的CNN实现。
主要贡献点:
- 全新的instance-aware跟踪器,使得SOT能够高效的处理MOT问题。 利用instance-aware的内在特性和交互性,改善相邻且相似目标的歧义性。
- 基于CNN的模型自适应更新方法更好地提升了SOT在MOT环境中的使用。
系统概貌
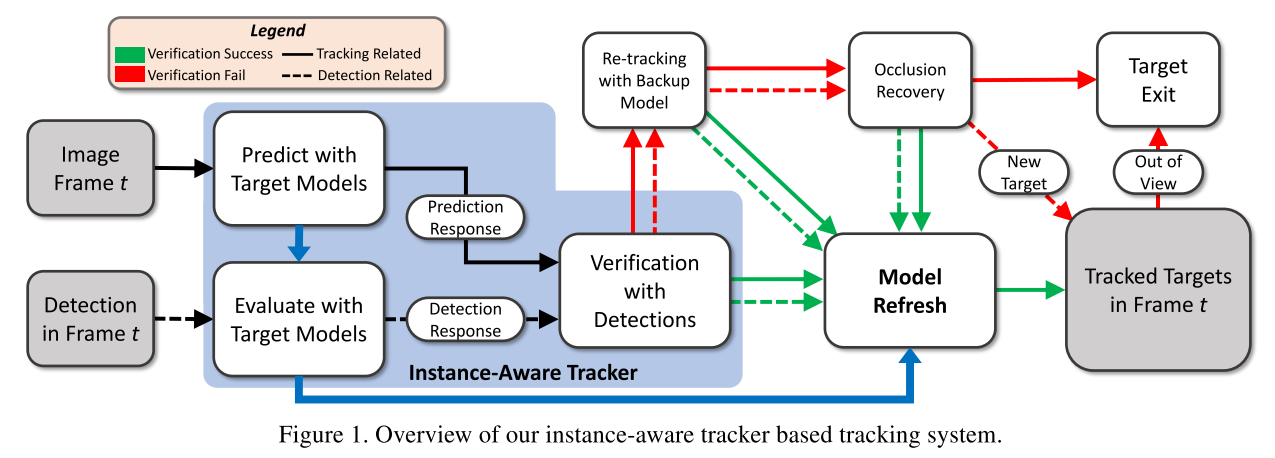
如上图所示,对于第$t$帧而言,系统的输入是第$t$帧的图像以及$t$帧中的检测结果。Instance-aware跟踪器的目标模型被用于预测每一条轨迹的位置,以及每一个检测的置信度。然后一个detection verification process将检测响应与预测响应进行一一配对。如果配对的检测比预测的框能够更好地enclosing目标(打分), 那么就用detection更新模型, 而没匹配成功的预测和检测将通过一个backup模型进行再次关联。再之后未配对的检测和预测送入到遮挡处理模块。最后处理轨迹的起始和终止。(这个套路其实是目前MOT的固定套路)
方法
问题定义
在第$t$帧,MOT任务可以认为是从图像$I^t$中的$M^t$个候选$O^t=\{x_j^t\}_{j=1}^{M^t}$中选择$N^t$个目标位置$\hat{X}^t = \{\hat{x}_i^t\}_{i=1}^{N^t}$ , 目标函数为:
$a^t = \{a_{ij}^t \in \{0, 1\}\}$指示第$t-1$帧中目标位置$\hat{X}^{t-1}$的第$i$个位置与当前帧中$X^t$的第$j$个目标匹配与否。 $W^t = \{w_i^t\}_{i=1}^{N^t}$ 是每一个模型的模型参数。 该参数有targets的表观和位置信息训练得到。$f(\cdot)$是评估匹配质量的函数, 其定义如下:
能量函数$g(\cdot)$是单目标跟踪的目标函数.
于是多目标问题的求解也就是单目标匹配的能量和关联变量$a$的求解。
Instance-Aware Tracker
IA tracker用来从两个层次求解$a^t, g_i(\cdot)$. 对于单独目标而言, $g_i(I^t, x_j^t)$应该具有对真实目标取得较高响应的同时抑制其他目标和背景的响应。而整体求解的时候, $a^t$需要让分配满足一一对应约束。
首先介绍目标函数$g_i(I^t, x_j^t)$ . 一般的SOT方法集中在鉴别目标和背景,并且允许目标发生一定的形变,但这就意味着对于不同目标之间表观的差异不够敏感。所以SOT直接用于MOT很容易导致漂移错误。在这篇文章中, MOT中跟踪单目标包含两个子问题:
从background中鉴别目标
区分不同的targets
$\theta_i^{t-1}$ 和$\epsilon_i^{t-1}$ 是模型参数, 因此$g_{det}(I^t, x_j^t;\theta_i^{t-1})$ 是度量位置$x_j^t$包含目标的指标, $g_{id}(I^t, x_j^t; \epsilon_i^{t-1})$度量的是目标$x_j$与$x_i$之间的相似度。
作者认为将两个问题拆开的优势是可以利用已有的较好的模型和数据集,比如第一项是行人检测,第二项是reid任务。
目标函数都采用脊回归的形式。 $g(z;\Phi) = \phi z^T$, 所以目标函数可以重写为
$T_{det}(., x_j^t), T_{id}(., x_j^t)$是$x_j^t$中心的图像变化, $\Phi_i^{t-1}=[\phi_i^{t-1}, \epsilon_o^{t-1}]$.
模型框架如下:
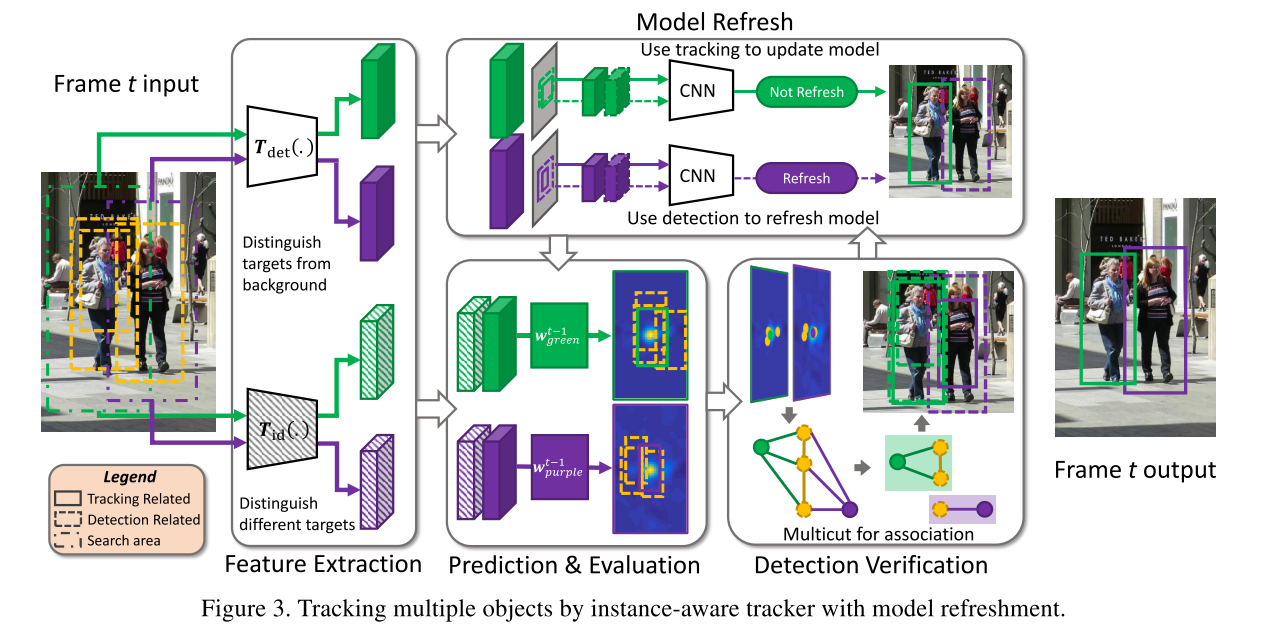
感觉文章叙述的挺乱的,浅显的东西被写的深奥难懂,我下面按自己的理解捋一捋
方法的主要流程:
- 对于第$t$帧首先利用单目标跟踪器预测每一条轨迹的当前位置$p$。(单目标预测)
- 然后将预测的候选位置和检测框都当做候选框,在于已经存在的轨迹进行关联,这里关联方法采用的是子图多割的方法。(子图多割)
- 多目标跟踪器的模型参数需要根据具体情况利用检测结果进行更新,而什么时候更新则依据一个基于CNN的二值分类器。(模型更新)
- 对于没有在子图多割中匹配成功的检测结果则需要进一步利用一个svm计算与剩余的未匹配的轨迹的相似度,然后再使用匈牙利算法进行二次关联。(遮挡处理)
- 最终进行轨迹起始和终止的判断。(轨迹管理)
下面我们讲讲这几个步骤
单目标预测
单目标预测其实就是SOT, 每个目标执行自己的单目标跟踪算法。而本文的单目标跟踪算法则使用的KCF模型。
假设轨迹$i$在第$t-1$帧中的目标的特征为$z^t$, 那么根据KCF,可以计算得到该轨迹对应的单目标跟踪器模型参数
其中$y$是label, $k$是核函数, $\lambda$是正则系数, $(\hat{\cdot})$是傅里叶变换。关于KCF的详细解释可以参考KCF, 然后对于预测的位置通过计算响应值来找到最可能匹配的位置
于是每一个目标都找到了其对应的最可能匹配的位置,作为在当前帧中的预测位置。
子图多割
这一部分就是文章中的Detection Verification。 作者认为, 只利用单目标跟踪器的话会导致有些预测位置发生冲突,因为没有全局考虑嘛。而只利用检测结果作为候选框,也就是传统teacking-by-detection的方法,则会受到detections中可能的false negative导致有些没检测到的响应的影响。(注:其实我觉得更主要的其实是必须依靠检测结果才能发现新的轨迹起点), 所以文章中将上一步单目标预测的结果和当前帧的检测结果放到一起作为当前帧候选的匹配框。但这又带来一个问题,就是预测和检测可能存在大概了的重叠,很难直接利用匈牙利类似的一对一算法进行匹配。所以作者采用了子图多割的策略,允许一条轨迹配对多个候选框。
作者构图方式:当前帧的所有候选框集合表示为$O^t = D^t \or P^t$, $D^t, P^t$分别表示检测结果和预测结果的集合。那么有图$G(V, E), V=\hat{X}^{t-1}\or O^t$, 其中$\hat{X}^{t-1}$表示上一帧获得的每条轨迹的位置点, (显然, 这里的子图多割就是希望将$O^t$中的点成group的分配给不同的$\hat{X}_i^{t-1}$, $E$文章中没说是否有约束条件,那么应该是任意两点都存在连接边。 图割问题的形式化表述为
这里$d_e$表示每条边的代价, $c_e$是示性量表示该条边是否关联, $0$表示关联, $1$表示断开,约束条件是用来约束每一个子图中的连接关系一致。文章中这部分没介绍清楚。$\mathcal{P}$应该是所有通路的集合, $p_{uv}$应该是两点之间存在的通路 $e$则表示一条边,于是约束的意义是:如果两个点$u,v$除了直连边之外的其他通路都是连接的, 那么直连边一定是连接的, 相反如果直连边是断开的,那么其他的通路必定也是断开的。
每条边上的代价函数
即当点分别来自于前一帧的目标和当前帧的候选框时,利用KCF计算相似度;当两点都来自于候选框的时候两者的相似度使用IoU计算;当两者都来自于前一帧的目标时,给定一个较大的负常数作为相似度。显然目标是不希望任意两个前一帧的目标被划分在一起。这个优化问题通过启发式方法求解。参见Siyu Tang的一系列多目标跟踪论文
这里不是每帧都是用检测结果进行验证,而是隔$F_V$帧验证一次,毕竟这个图割还是挺耗时的。
模型更新
KCF跟踪器是每一帧都进行更新的,但是对于MOT任务而言,如果每一帧都进行更新的话可能会导致将噪声更新进模型参数中,从而导致跟踪漂移,所以文章专门设计了一个基于CNN的二值分类器用于判断当前是否需要用检测结果更新模型参数。而这个分类器的解释是判断检测结果和预测结果哪一个能够更好地enclosing真实的target。
该分类器采用强化学习的方式进行训练。模型训练的正负样本分别依靠下述规则生成。
- 模型更新了参数,但是预测的框与真实ground truth的iou高于检测框与ground truth的iou, 这时候认为产生了负样本, 将检测和预测concate一起作为负样本的特征。
- 模型没有更新参数,但是显然检测框与预测框能够更好地enclose ground truth, 这时候认为产生了正样本, 将检测和预测特征concate一起作为正样本的特征。
这里的正负样本是指是否需要更新模型参数。 另外还有一个问题:可能一个subgraph中多个detection如何选择,文章中没看到。我觉得两种方式,一种就是分别每一个detection都和prediction concate一次作为样本,另一种就是选择enclose目标最好的detection与prediction做concatenation。
Back up 文章中这里还设计了一个备份的策略,就是在更新模型的时候把上一个模型参数暂时保存起来,然后观察更新的模型参数合不合适,不合适就继续采用之前的模型参数。而判断模型参数合不合适的方式是在$t+1$帧看模型能不能与检测匹配成功。
遮挡处理
对于剩下的没有跟踪成功的轨迹和没有匹配的检测,作者认为是由于遮挡造成的,所以需要对这些轨迹和样本进行再一次关联。而这次关联则与传统的MOT方法思想一样,计算检测和轨迹的相似度,然后通过匈牙利算法进行匹配。
在计算相似度时采用的是SVM分类器, 每个配对的特征设计如下
$\varepsilon. \epsilon, \eta$分别表示(x,y)坐标和高度。 $\bar{\eta}$则表示均值。$b_1$表示的是轨迹开始出现遮挡时的bounding box, $b_2$则是轨迹遮挡消失那一刻的bounding box。 $\phi_{hist}$是颜色直方图的intersection。
这部分和层次匹配的思想非常像
轨迹管理
- 轨迹起始: 前面几个阶段都没有关联成功检测作为新的轨迹的起点
- 轨迹终止:如果bounding box超出视野认为轨迹终止; 如果轨迹连续多帧没有匹配到detection则认为轨迹终止。
其他
还有一点需要说明的就是在使用KCF进行预测时的feature从哪里来, 正如文章中的fig3所示, 这个特征有两部分组成, 一部分是det网络提取的特征,一部分是re-id网络抽取的特征。在实验中分别使用PAFNet和PartNet作为检测和重识别网络。
现在再来看方法的系统图就容易看懂了
实验
特征抽取器: 检测部分使用的PAFNet, 身份重识别部分采用的PartNet的全卷积层输出。
训练策略: CNN当错误发生时以Batchsize=32, lr=0.001迭代5次。
实验结果:
$T_V$
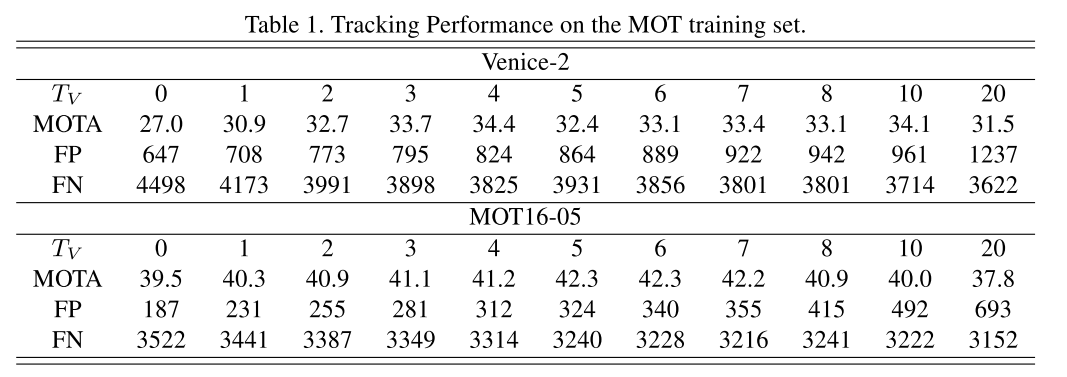
$T_V$对FP和FN指标会产生影响, 当$T_V$增大时,也就是长时间不用detection矫正跟踪,那么可能会出现更多的FP; 当$T_V$减小时,极限是每帧都更新,那么就会因为漏检导致轨迹过早结束,使得FN增大。
Ablation Study
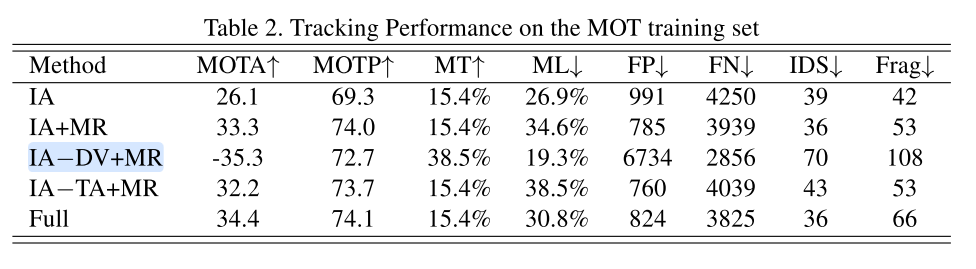
MR: Model Refresh
DV: detection verfication
TA: 表示开始KCF使用的特征
可以看到当DV不使用时,也就是全靠单目标KCF跟踪器处理MOT,然后MOTA非常差, 而使用VGG16抽取的特征替代本文中来自于ReID和Det的特征效果也有些许下降,这可能是因为训练不够充分。
Results on Test Sequences
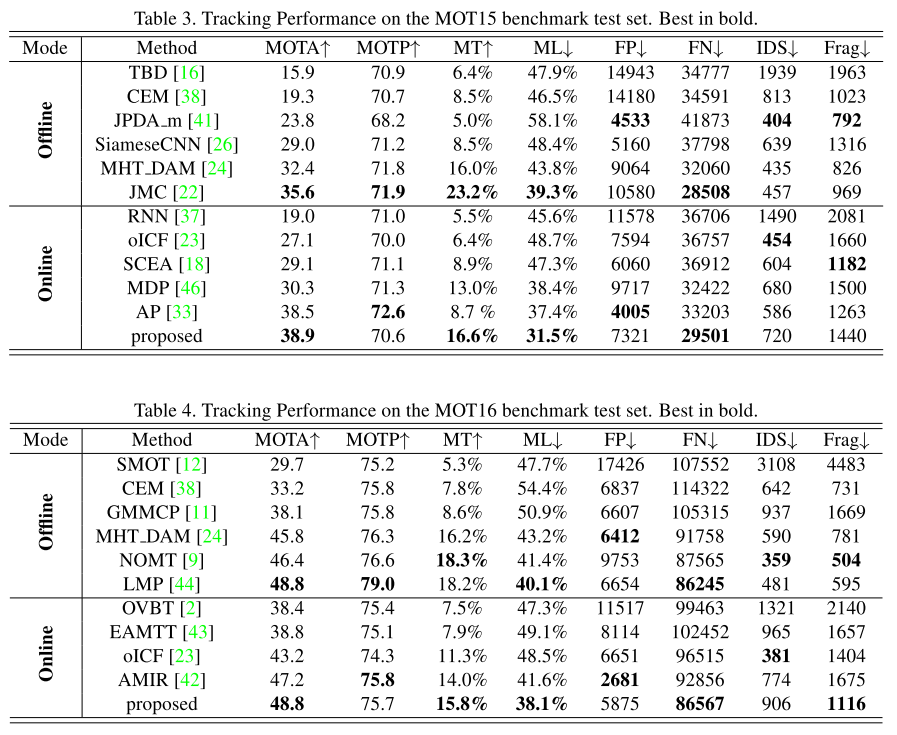
总的来说性能还行,但是对比的方法并不是state-of-the-art的方法。
Conclusion
这篇文章也是一种使用SOT处理MOT的方法,同一类的方法有DMAN和STAM算法。 而这个的主要贡献点可能在于使用子图多割模型处理多个候选框对应一个target的问题。
其实将预测和检测融合在一起再进行匹配跟踪本身就能取得一个相当的实验结果。
所以可以提供借鉴的点在于:使检测更加的准确。比如利用预测减少FN, 利用refine减少FP等。这也是我目前在做的工作。
本文作者 : zhouzongwei
原文链接 : http://yoursite.com/2019/06/01/Instance-Aware-Tracker/
版权声明 : 本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明出处!
知识 & 情怀 | 赏或者不赏,我都在这,不声不响

