阅读笔记-Social Attention Modeling Attention in Human Crowds
摘要
机器人在拥挤场景下的导航需要能够预测准确,有效的行人轨迹。之前的方法在预测行人轨迹时将行人之间的交互建模为临近度函数。 但这种假设有时候并不成立,比如距离近的目标可能因为和机器人的速度方向一致从而相对于较远的速度不一致的目标对于冲突规避的影响反而小。所以这篇文章不是基于距离度量刻画目标之间的相互影响,而是通过一种Social Attention的机制去刻画行人之间的相互影响的权重。
介绍
- 早期的一部分工作是从crowds场景中建模独立个体的运动模式,从而预测每个目标的运动轨迹。但这种方法每个个体独立,并没有考虑行人之间可能存在的相互影响,进而导致robot的路径规划是次优的。
- 另外一些方法通过空间局部交互模型建模交互目标的未来轨迹的联合分布实现轨迹预测。这种方法能够建模轨迹之间的相互影响,但是该类方法只考虑了局部邻域内的其他目标, 而在真实场景中往往并不是这样。比如走廊对面迎面走过去的两个人,即使相距很远,对对方速度也是有影响的;同样的如果两个人很近但是相反方向运动,那么并不会对对方产生影响。所以行人与行人之间的相互作用并不局限于相对距离,与速度,目的地等都有关系。
- 这篇文章提出利用RNN建模crowd场景中多人的轨迹状态,同时考虑时空线索。 human-human之间交互通过soft attention方式建模,而不仅仅考虑局部邻域目标。
问题定义
假设每一帧图像上目标都可以检测和跟踪。当然允许目标在任意时刻进入、离开视野。时刻$t$ 的agent $i$的坐标位置表示为$(x_i^t, y_i^t)$, 于是问题可以定义为:
给定时刻$t=1, \cdots, T_{obs}$中agents的位置坐标$\{(x_i^t, y_i^t)|i=1, 2, \cdots, N\}$, 希望预测每条轨迹的未来的位置$\{(\hat{x}_i^t, \hat{y}_i^t)| t=T_{obs+1}, \cdots, T_{pred}\}$
方法
文章主要解决的问题,是针对于局部邻域内目标相互影响的一类方法,回答
Which surrounding agents do humans attend to, while navigating a crowd?
就是希望能够从数据中抽取特征并推理出目标之间相互影响的程度。
Spatio-Temporal Graph Representation
使用时空图刻画时许中agents之间的关系$\mathcal{G}=(\mathcal{V, \varepsilon_S, \varepsilon_T})$, 分别表示所有的agents和空域,时域的关联边集合, 如下图所示2帧之间的st-graph
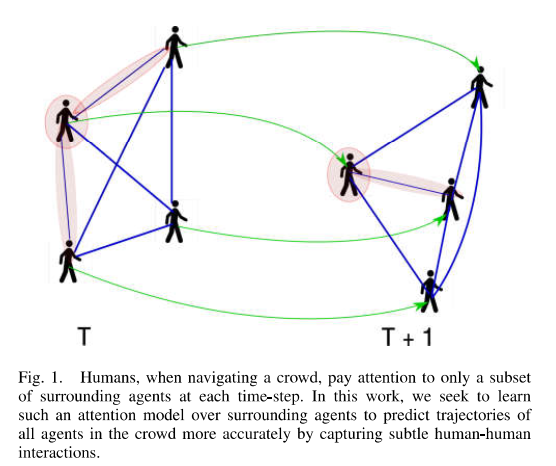
时刻$t$中顶点$v$关联的特征向量是$x_v^t=(x_v^t, y_v^t)$, 里面对应的是两个方向的坐标值,注意不要混淆。 空间边$(u, v)\in\varepsilon_s$关联的特征向量$x_{uv}^t = (x_{uv}^t, y_{uv}^t)$表示当前时刻从$u$到$v$的矢量。类似的,时间边$(u, u)\in \varepsilon_T$关联的特征向量$x_{uu}^t=(x_{uu}^t, y_{uu}^t)$表示从$t-1$到$t$时刻的向量,于是得到下图:
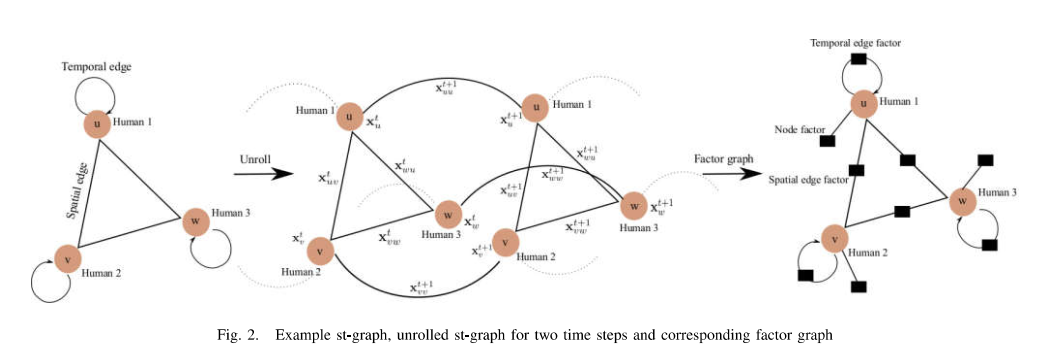
最左边的是rolled st图, 中间是将左图按照时间展开的图,每条边和顶点都对应其关联的特征向量。右图是接下来要将的网络待学习的权重参数。
Model Attention
整个模型共包含3个部分:nodeRNN, EdgeRNN和Attention Module。其中Attention Module刻画了每个节点关联到的时空边的关系,然后得到一个综合的时空边特征,该特征与节点的特征融合送入NodeRNN中估计node的状态。
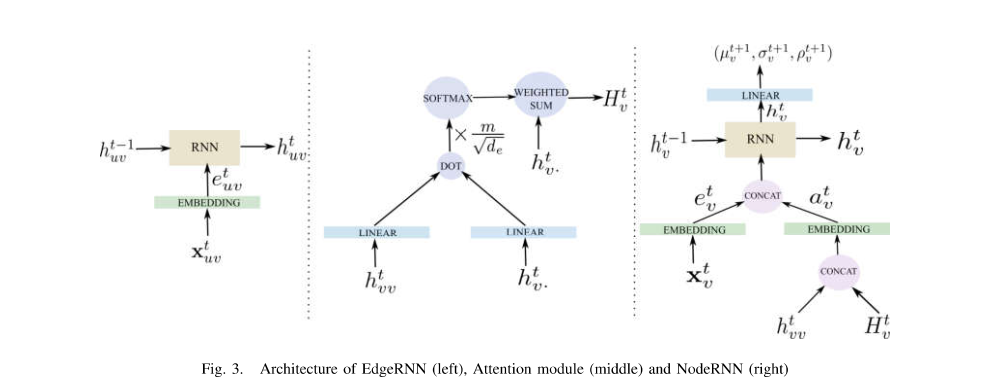
EdgeRNN
Fig3的左图所示,标准的RNN模型,输入特征经过一定的embeding,送入RNN模块中刻画当前时刻的特征。
Attention Module
Fig3的中间图所示,其目的是想获得与该顶点相关联的边对于当前顶点变化的影响。$h_{vv}$ 表示该顶点的自相关向量, $h_{v.}$表示该顶点射出去的边的特征, 经过标准的scaled dot product attention方法获得每个$h_{vv}, h_{vk}$的相似度
于是加权之后的时空边赋予顶点的特征为:
Node RNN
Fig3的右图显示的Node RNN的结构,其相对于标准的RNN只是将时空边提供node的特征向量与顶点本身的特征向量进行了embeding,然后送到RNN结构中。
最终得到预估的2d高斯分布参数
损失函数
训练的过程中希望最大后验概率, 于是损失函数采用交叉熵损失:
推理过程
首先利用观测到的前$T_{obs}$帧结果放到网络中然后预测得到后续时刻的高斯分布参数, 再从这些高斯分布中采样得到每一时刻的预测位置。
这个采样过程是不确定的,只知道服从对应的高斯分布。在未知准确的位置时,比如$T_{obs}+1$时刻,使用预测的值代替真实的位置继续评估后续时刻的高斯参数。
评估
所使用的数据集 ETH, UCY总共 5个结合, 1536个行人, 帧率25FPS, 每隔10帧标注一次。在使用的过程中通过插值的方式是的每一帧都有对应的gt。
评估指标。
- Average Displacement Error, 逐一统计每一时刻的预测值和真实值的偏差,然后计算均值。
- Final Displacement Error, 只计算$T_{pred}$之后的预测位置和真实位置的偏差均值。
操作细节
nodeRNN的隐状态长度128, edgeRNN隐状态长度256, embedding层的长度64, 激活函数ReLU。 batchsize=8, lr=0.001, 训练了100个epoch。
代码: github:srnn-pytorch
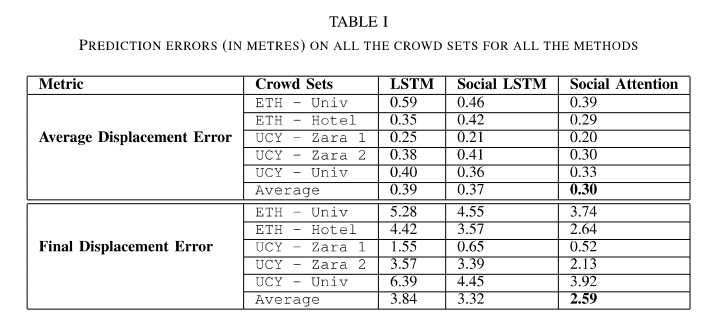
定量的实验结果
定性分析
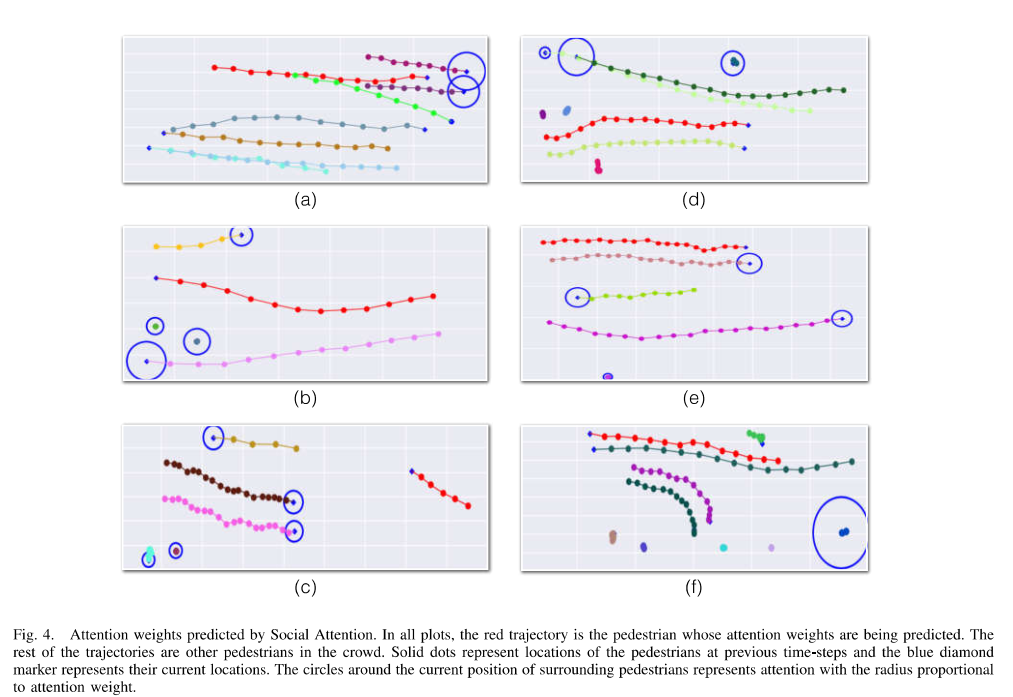
论文给出了一些attention的示例, 上图中圈的大小表示了相对attention权重的大小, 蓝色顶点表示当前时刻的每条轨迹的位置, 红色的轨迹是主体轨迹, abc图是成功的案例, def则存在着一些问题需要在未来工作中解决。d中深绿色的轨迹距离较远且速度方向不同但权重却挺大。同样的e中浅绿色的轨迹, f中更明显,几乎静止的运动反方向点却对轨迹预测影响很大,这些问题都需要进一步解决。
总结
In this work, we have presented an attention-based trajectory prediction model, Social Attention, that learns the relative influence of each pedestrian in the crowd on the planing behavior of the other, and accurately predicts their future trajectories. We use an RNN mixture to model both the temporal and spatial dynamics of trajectories in human crowds. The resulting model is feedforward, fully-differentiable, and is jointly trained to capture human-human interactions between pedestrians.
本文作者 : zhouzongwei
原文链接 : http://yoursite.com/2019/07/10/SocialAttention/
版权声明 : 本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明出处!
知识 & 情怀 | 赏或者不赏,我都在这,不声不响

